18 Décomposer
Prédire une variable dépendante à partir de variables indépendantes n’est pas la seule façon de décortiquer des données. Il existe des techniques statistiques qui réorganisent l’information (les corrélations) des variables. Il s’agit des analyses factorielles. Elles s’intéressent plus à la structure des corrélations qu’aux systèmes qui les lient. Bien qu’il s’agisse de nuances sur le plan statistique, les deux côtés d’une même médaille, les différences sont importantes sur le plan théorique. Plutôt que de parler de cause à effet, c’est plutôt la structure sous-tendant les variables qui est d’intérêt.
À titre d’illustration, la Figure 18.1 présente à gauche la régression, \(x_1\) prédit \(x_2\), et à droite le facteur \(F\) qui est la source de \(x_1\) et \(x_2\).
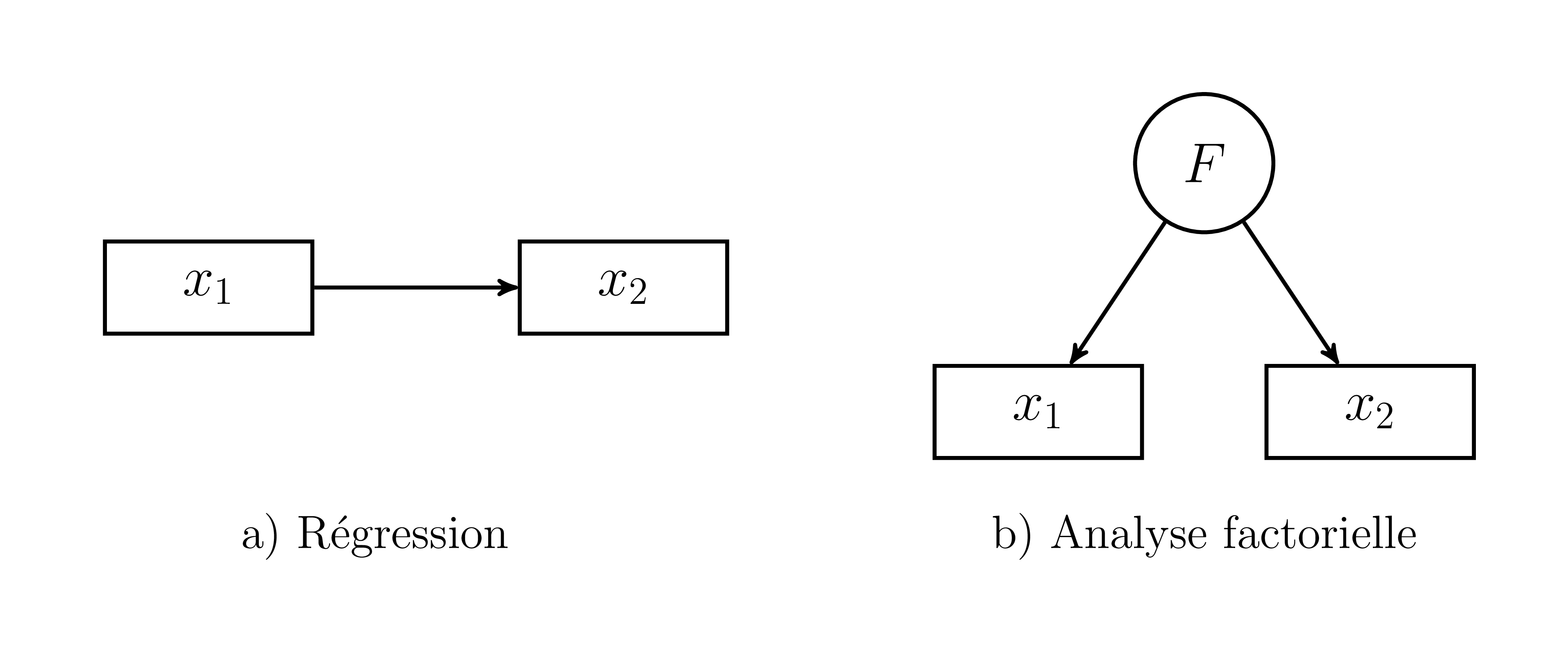
Figure 18.1: Les représentations de la régression et l’analyse factorielle.
Plusieurs éléments permettent de mieux mettre en évidence les différences entre les deux modèles. Les variables manifestes \(x_i\) sont des mesures empiriques mesurées auprès d’unités d’observations. Elles sont représentées par des rectangles. Le facteur \(F\) est représenté par un cercle. Il s’agit d’une variable latente, une variable non observée et inférée à partir des variables manifestes. Par exemple, les habiletés en lecture \(x_1\) sont liées aux habiletés en mathématique \(x_2\). D’un côté, mieux le participant lit, plus il répond rapidement et exactement aux questions de mathématique. De l’autre côté, les habiletés en mathématique et en lecture peuvent aussi être liées à un facteur commun : l’intelligence. Les habiletés en mathématique et en lecture sont observables par des évaluations, mais l’intelligence s’infère à partir de ces tests29. C’est là que les analyses factorielles entrent en jeu.
Les analyses factorielles sont utilisées, par exemple, lors de la création d’un test psychométrique. Le psychométricien s’intéresse à connaître quels items (variables manifestes) sont liés sur quelle dimension et à quel degré. Les items communs sont alors liés fortement sur certains facteurs et faiblement sur d’autres. Le facteur à un fort potentiel explicatif pour les items qui lui sont fortement liés, voire même représente un concept, thème ou construit théorique commun partagé entre ces items.
Dans ce livre, deux types d’analyse factorielle sont abordées : l’analyse en composantes principales et l’analyse factorielle. La première est un modèle athéorique (sans hypothèses sous-jacentes) à la structure des données, alors que la seconde présuppose, comme hypothèse, un ou des facteurs latents communs. Sur le plan computationnel, l’analyse en composantes principales réorganise tous les facteurs, alors que l’analyse factorielle extrait un nombre donné de facteurs. Les analyses factorielles se distinguent également en deux catégories : exploratoire et confirmatoire. Spécifiquement, ces deux termes distinguent si l’analyse contraint (confirmatoire) ou non (exploratoire) la structure factorielle. Tout cela sera abordé plus en détails dans les prochains chapitres.
18.1 L’analyse en composantes principales
L’analyse en composantes principales (ACP) fait partie de la famille des analyses factorielles exploratoires. Elle consiste à réorganiser des variables corrélées (une matrice de covariance) en nouvelles variables orthogonales (décorrélées) les unes des autres. Ces nouvelles variables sont des composantes principales, axes principaux ou encore des dimensions. Il s’agit d’une technique à la fois géométrique et statistique dont les champs d’application vont de la psychologie, la sociologie, la biologie, la chimie, la physique quantique jusqu’aux mathématiques pures. Elle ne se limite donc pas qu’à la psychométrie.
L’ACP prend comme base la matrice de corrélation30 et la réorganise (essentiellement une rotation géométrique) afin que les nouvelles dimensions soient indépendantes l’une de l’autre. L’ACP procure trois informations cruciales sur une matrice de corrélation, les valeurs propres et les vecteurs propres, desquels les loadings31 sont calculables.
18.1.1 Les valeurs propres
Les valeurs propres (eigenvalues) représentent l’aspect crucial de l’ACP, soit l’importance de chaque composante à représenter les variables. Plus les variables sont liées sur un même axe (en nombre et en poids), plus la valeur propre de cet axe sera élevée. Mathématiquement, les valeurs propres sont représentées par un vecteur \(\Lambda\) ou une matrice diagonale \(\text{diag}(\Lambda) = \mathbf{\Lambda}\).
La somme des valeurs propres est égale à la somme des variances, ce qui équivaut pour la matrice de corrélation à \(p\), le nombre de variables. Comme il s’agit du potentiel maximal de ce qui peut être expliqué et que les valeurs sont une part de ce total, il est possible de calculer leur importance relative par des pourcentages. Par exemple une valeur propre de 5 sur un total de \(p=10\) variables signifie que l’axe correspondant explique \(5/10 \times 100 = 50\)% de la variance de la matrice de corrélation. En d’autres termes, la valeur propre est une bonne mesure de l’importance d’une dimension.
En identifiant les composantes principales, l’ACP révèle du même coup l’importance de chacune d’elle. Il est alors naturel de les classer en ordre décroissant32.
18.1.2 Les vecteurs propres
Les vecteurs propres (eigenvectors) sont les axes d’orientation des valeurs propres dans le plan de la matrice de corrélation originale. Chaque axe représenté est orthogonal (indépendant) aux autres. Ils sont également normalisés, c’est-à-dire des vecteurs unitaires (la somme de leur carré est égale à 1). Mathématiquement, les vecteurs propres sont représentés par une matrice \(\mathbf{V}\).
18.1.3 Les loadings
Les vecteurs propres avec les valeurs propres permettent de calculer les loadings. Ils correspondent au lien entre chaque axe et les variables. En d’autres termes, les loadings correspondent au degré selon lequel une variable corrèle avec un facteur. C’est l’importance relative de chaque variable sur chaque axe. Par exemple, les variables fortement associées partageront de très forts loadings avec un certain axe, alors que celles faiblement associées auront des loadings beaucoup plus faibles avec les axes qu’elles ne partagent pas. L’équation (18.1) détaille cette relation.
\[\begin{equation} \mathbf{L} =\mathbf{V}\mathbf{\Lambda^{\frac{1}{2}}} \tag{18.1} \end{equation}\]
Lorsque dérivés d’une matrice de corrélations, les loadings sont les corrélations entre l’axe et la variable. C’est la force des liens allant de \(F\) aux \(x\) dans la Figure 18.1. En termes d’analyse factorielle, il s’agit de scores factoriels.
Pour mieux illustrer, les valeurs propres, les vecteurs propres, les loadings, mais surtout la décomposition en axes principaux, la section suivante présente un exemple pour mettre le tout en commun.
18.2 Création de données
La création de données pour une ACP est très simple. Il suffit de créer une matrice de covariance ou de corrélation. Dans cet exemple, 10 participants sont mesurés sur deux variables ayant une corrélation de .80 entre elles.
# Pour la reproductibilité
set.seed(42)
# Quelques paramètres
n <- 10
rho <- .80
S <- matrix(c( 1, rho,
rho, 1),
ncol = 2, nrow = 2,
dimnames = list(nom <-c("x1", "x2"), nom))
jd.acp <- MASS::mvrnorm(n = n,
mu = rep(0, 2),
Sigma = S,
empirical = TRUE)L’argument empirical = TRUE assure que la matrice de corrélation de la population est identique à celle de l’équation, \(\mathbf{\Sigma} = \mathbf{S}\), ce qui facilite l’interprétation de cet exemple.
La Figure 18.2 illustre la répartition des 10 participants par rapport aux variables 1 et 2. La ligne pointillée désigne la droite de régression qui les relie, soit la pente \(\beta = .8\).
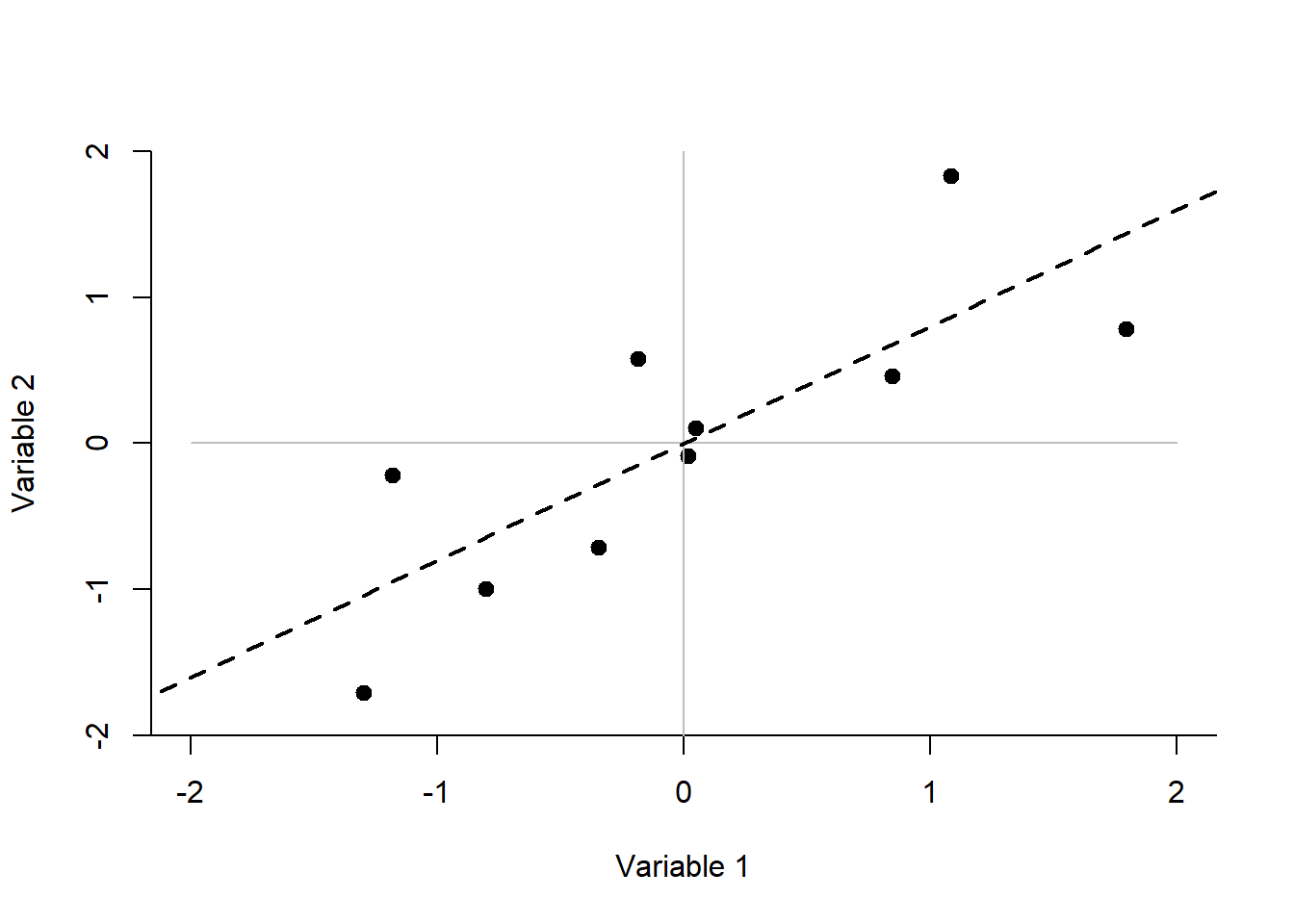
Figure 18.2: Présentation des données (jd.acp).
18.3 Analyse
Il existe plusieurs fonctions dans R, mais aussi dans des packages, pour réaliser l’ACP. L’analyse en soi n’a rien de sorcier (cela en supposant la statistique ne repose pas sur la magie), c’est surtout l’emballage (arguments, graphiques et sorties) qui change en fonction de la méthode utilisée. Ces fonctions précalculent et extraient les statistiques désirées, rien que l’utilisateur ne peut faire lui-même.
Il existe quatre fonctions de base R pour faire l’analyse en composantes principales. Les deux principales, eigen() et svd(), fournissent des résultats virtuellement identiques, mais se distinguent sur leur limite de ce qu’elles peuvent accomplir. Les deux autres, princomp() etprcomp()`, sont leur emballage respectif. Les détails des calculs seront présentés dans une autre section, Les calculs de l’analyse en composantes principales.
18.3.1 eigen()
La fonction eigen() est celle des puristes. Rudimentaire, elle prend comme argument une matrice de covariance ou de corrélation et calcule les valeurs propres (values) et les vecteurs propres (vectors).
# L'analyse de la matrice de corrélation
res.eig <- eigen(cor(jd.acp))
# Les valeurs propres
res.eig$values
> [1] 1.8 0.2
# Les vecteurs propres
res.eig$vectors
> [,1] [,2]
> [1,] 0.707 -0.707
> [2,] 0.707 0.707
# Les loadings
res.eig$vectors %*% diag(sqrt(res.eig$values))
> [,1] [,2]
> [1,] 0.949 -0.316
> [2,] 0.949 0.316La fonction eigen() ne fonctionne qu’avec des matrices carrées et est donc très robuste afin d’éviter de mauvais arguments.
18.3.2 svd()
L’analyse de décomposition en valeurs singulières (singular value decomposition, SVD) est généralement recommandée, car elle est computationnellement plus robuste que eigen(). Un puriste R choisirait probablement la fonction eigen(), car la fonction est plus robuste aux erreurs de l’utilisateur.
# L'analyse de la matrice de corrélation
res.svd = svd(cor(jd.acp))
# Les valeurs propres
res.svd$d
> [1] 1.8 0.2
# Les vecteurs propres
res.svd$v
> [,1] [,2]
> [1,] -0.707 -0.707
> [2,] -0.707 0.707
# Les loadings
res.svd$v %*% diag(sqrt(res.svd$d))
> [,1] [,2]
> [1,] -0.949 -0.316
> [2,] -0.949 0.316Les résultats sont identiques à la fonction eigen(). Le lecteur attentif aura toutefois remarqué que res.svd$v n’égale pas exactement res.eig$vectors à cause des signes négatifs du premier vecteur propre. Toutefois, il convient d’affirmer que c’est seulement la polarité qui est différente, comme si un vecteur propre indiquait le nord et l’autre le sud, alors que les deux sont dos à dos, exactement à \(180^{\circ}\).
La fonction svd() est plus générale et peut utiliser des matrices rectangulaires. Il faut faire attention de ne pas lui fournir le jeu de données et bien la matrice de covariance ou de corrélation.
Il convient également d’ajouter que, comme \(\mathbf{\Sigma} = \mathbf{S}\) (à l’aide de l’argument empirical = TRUE de MASS::mvrnorm()), il n’était pas nécessaire de générer de données pour réaliser les analyses, car svd(S) ou eigen(S) offre les mêmes résultats. C’est la matrice de corrélation qui est décomposée et non les participants. Remarquez d’ailleurs comment l’ACP est indépendante de la taille d’échantillon33.
18.4 Représentations des résultats
La Figure 18.3 montre à gauche les données originales sur les axes représentés par les deux variables (une reprise de la Figure 18.2). À droite, il s’agit de la rotation trouvée par l’ACP (eigen() ou svd()). Les participants conservent entre eux les mêmes distances par rapport aux autres, mais aussi par rapport aux axes originaux représentés par des lignes pointillées. C’est vraiment l’orientation du plan qui change34.
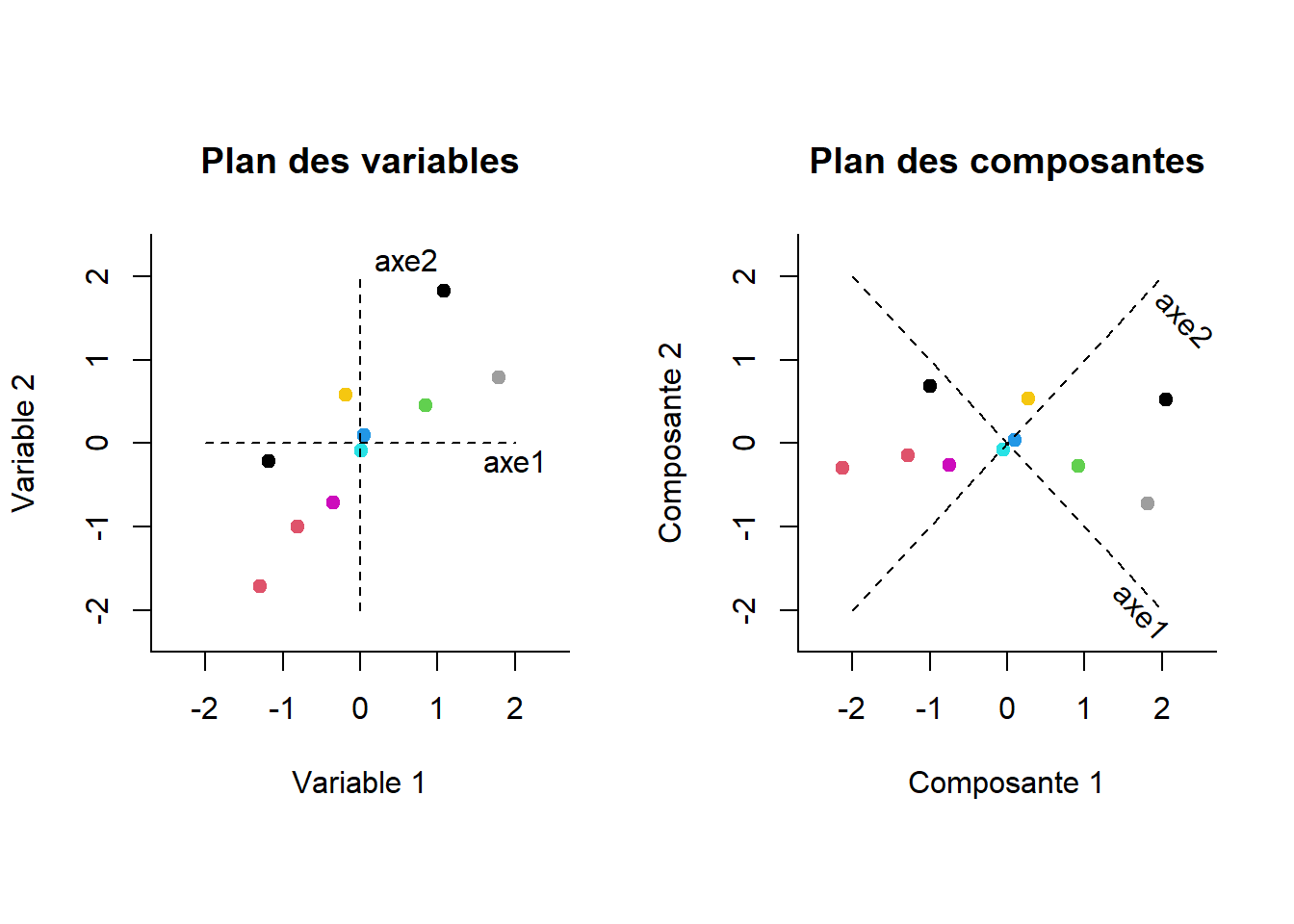
Figure 18.3: Les représentations des participants selon les variables (gauche) ou selon les composantes principales (droite).
La première composante retrouvée correspond (approximativement) à la droite de régression de la Figure 18.2. Il s’agit de l’information partagée par les deux variables : c’est leur axe commun. L’erreur résiduelle correspond au deuxième axe (l’axe vertical). Cette intuition est fondamentale : une valeur propre élevée implique une dimension où la variance est partagée entre les variables, alors qu’une valeur propre plus faible aura tendance à représenter une dimension de résidus, et par définition, de l’informations non partagées.
La Figure 18.4 offre une vue de l’agencement des variables sur les deux axes. Il s’agit des loadings des variables dans l’espace des composantes. Cette représentation est assez triviale pour deux variables, mais peut devenir très pertinente lorsque plusieurs variables (ou items) sont concernées. Il est possible d’observer alors des regroupements d’items sur les facteurs. Elle se limite toutefois à une ou deux composantes étant donné la complexité de réaliser et d’interpréter des figures de trois dimensions et plus.
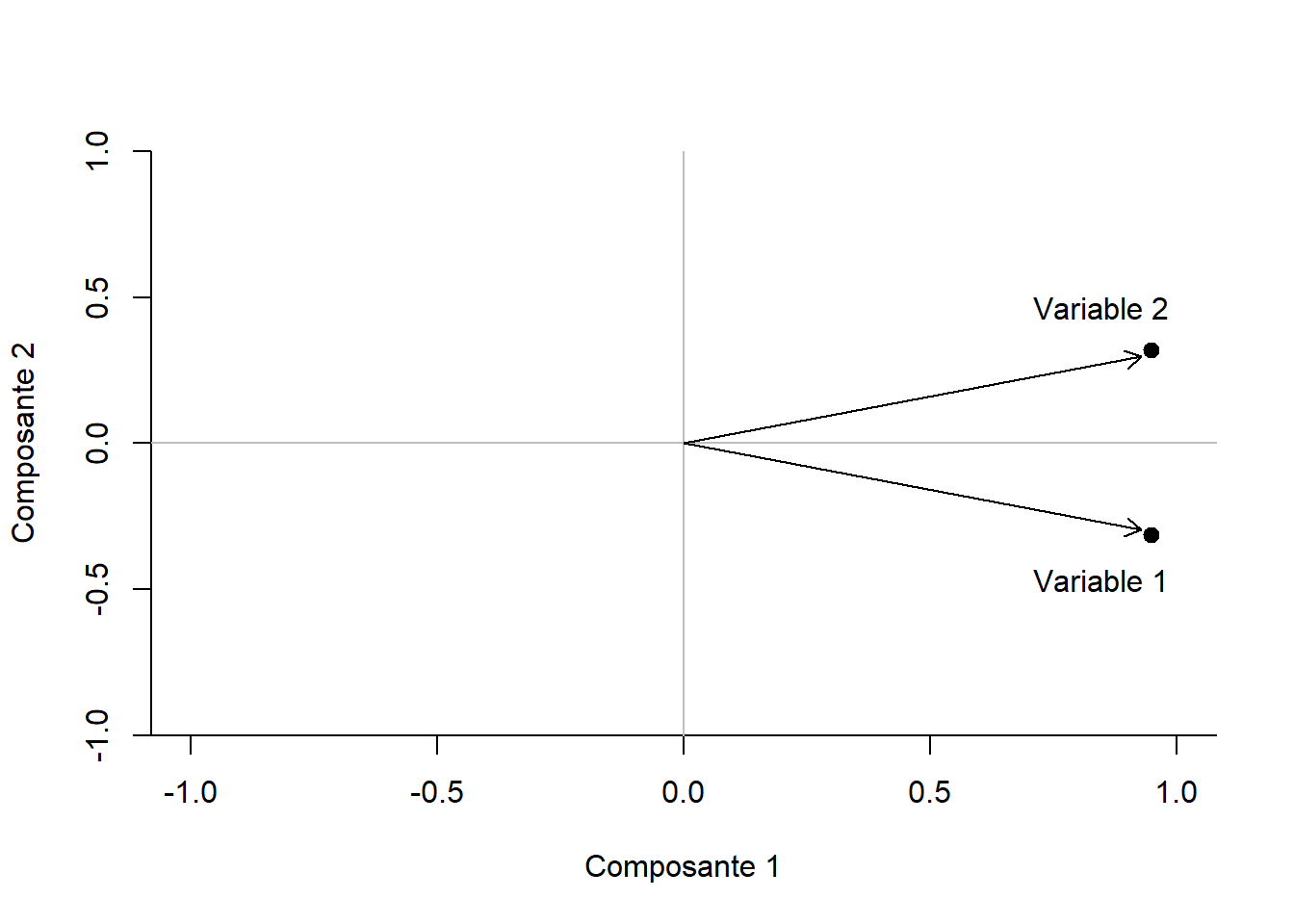
Figure 18.4: La représentation des variables selon les composantes principales.
18.5 Les calculs de l’analyse en composantes principales
Il existe plusieurs techniques mathématiques pour retrouver les valeurs propres. Elles ont différents avantages selon l’objectif visé. Elles ont certainement toutes en commun que, plus le nombre de variables augmente, plus le désir de les calculer par ordinateur est grand. Ici, une technique est présentée dans l’optique de bien vérifier qu’aucun sortilège computationnel n’opère derrière le logiciel35.
Une des méthodes pour réaliser l’ACP est de résoudre le polynôme caractéristique. Autrement dit, il s’agit de retrouver tous les inconnus \(\lambda\) (les valeurs propres) du polynôme caractéristique, soit l’équation (18.2)
\[\begin{equation} |\mathbf{S} - \lambda \mathbf{I}| = 0 \tag{18.2} \end{equation}\]
qui représente le déterminant (indiqué par les \(||\)) nul de la matrice pour différent \(\lambda\).
En conservant l’exemple précédent, on remplace la matrice symétrique
\[ \mathbf{S} = \left( \begin{array}{cc} 1 & .8 \\ .8 & 1 \end{array} \right) \]
dans l’équation (18.2), ce qui donne,
\[ \left| \left( \begin{array}{cc} 1 & .8 \\ .8 & 1 \end{array} \right) -\lambda \left(\begin{array}{cc} 1 & 0 \\ 0 & 1 \end{array} \right) \right| = 0 \]
et ainsi
\[ \left| \left( \begin{array}{cc} 1 & .8 \\ .8 & 1 \end{array} \right) - \left(\begin{array}{cc} \lambda & 0 \\ 0 & \lambda \end{array} \right) \right| = 0 \]
et ainsi
\[ \left| \left( \begin{array}{cc} 1 - \lambda & .8 \\ .8 & 1 - \lambda \end{array} \right) \right| = 0 \]
Le polynôme caractéristique est retrouvé en calculant le déterminant de la matrice, soit le produit de la diagonale moins le produit des valeurs hors diagonale36,
\[ (1-\lambda)(1-\lambda) - (.8)(.8) = 0 \]
ce qui donne
\[\begin{equation} \lambda^2 - 2 \lambda +.36 = 0 \tag{18.3} \end{equation}\]
où il est maintenant possible de résoudre \(\lambda\) avec la très célèbre équation (18.4).
\[\begin{equation} a\lambda^2+b\lambda+c=0 \implies \lambda=\frac{-b \pm \sqrt{b^2-4ac}}{2a} \tag{18.4} \end{equation}\]
Les solutions sont \(.2\) et \(1.8\). Graphiquement, la Figure 18.5 illustre l’équation polynomiale caractéristique (18.3).
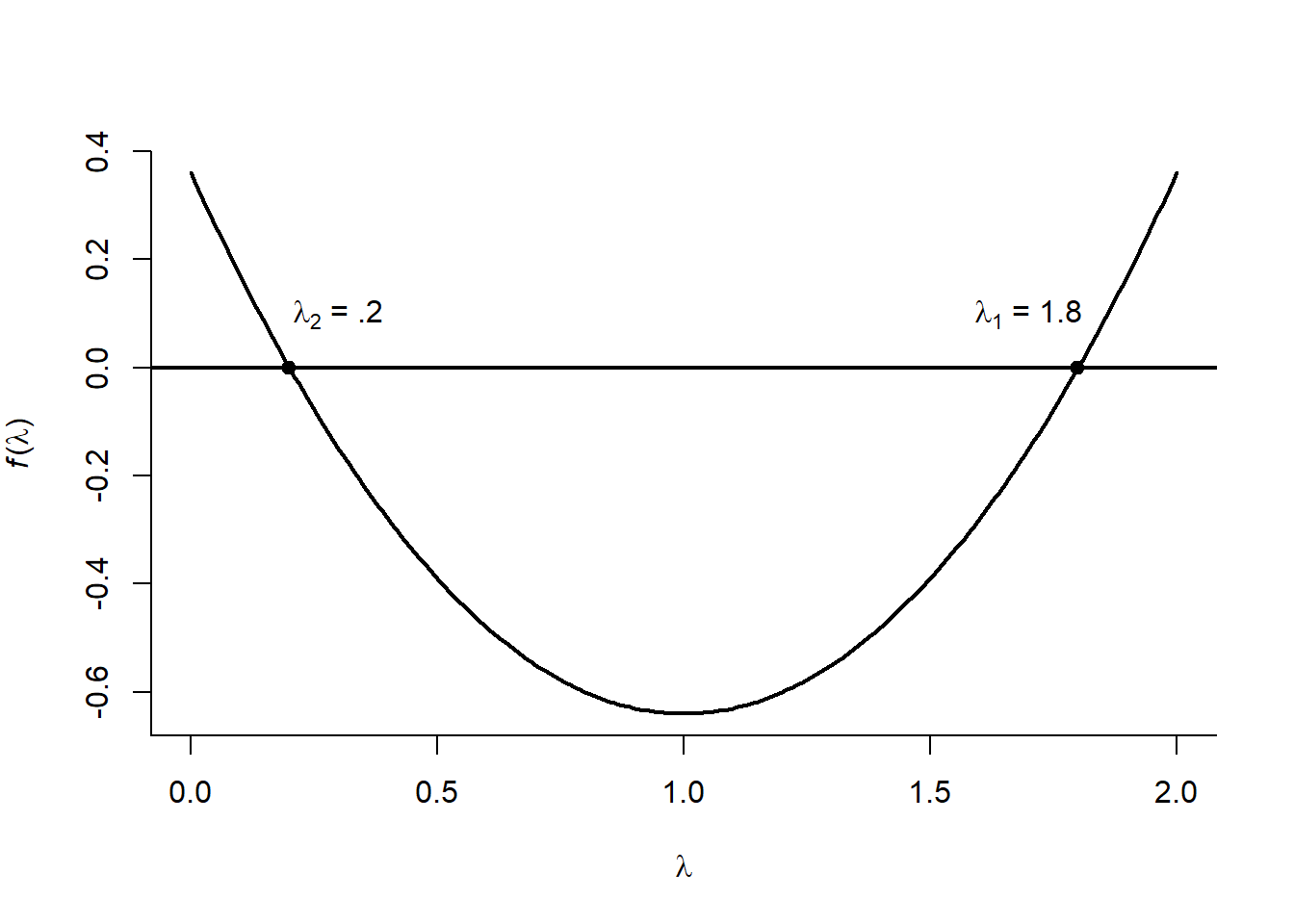
Figure 18.5: L’équation du polynôme caractéristique.
Cela fait beaucoup de mathématiques. Est-il possible d’y arriver plus simplement avec R? Le package pracma (Borchers, 2022) offre une fonction charpoly() qui permet de trouver le polynôme caractéristique d’une matrice. R de base a aussi une fonction permettant de résoudre des polynômes, polyroot(). Avec ces deux fonctions, il est possible de refaire toute la présente section. Il faut toutefois noter que les coefficients polynomiaux donnés par charpoly() doivent être inversés pour polyroot(). À noter également, l’ajout de la fonctionRe() assure que les valeurs propres sont des nombres réels et non imaginaires37. Par convention, les valeurs propres sont ordonnées de façon décroissante, bien qu’elle n’est originalement pas d’ordre particulier.
# Trouver les coefficients polynomiaux
coef.poly <- pracma::charpoly(S)
# Inverser l'ordre
coef.poly <- coef.poly[length(coef.poly):1]
# Trouver les valeurs à 0 (valeurs propres, E)
E <- Re(polyroot(coef.poly))
# Mettre en ordre décroissant
E <- sort(E, decreasing = TRUE)
# Résultats
EEt voilà! Les valeurs propres sont retrouvées. Pour les vecteurs propres, c’est un peu plus compliqué.
L’objectif est de trouver pour chaque valeur propre la solution de l’équation (18.5)
\[\begin{equation} \left(\mathbf{S} - \lambda_i \mathbf{I} \right) v_i= 0 \tag{18.5} \end{equation}\]
soit pour \(\lambda = 1.8\) :
\[\left[ \left( \begin{array}{cc} 1 & .8 \\ .8 & 1 \end{array} \right) - 1.8 \left(\begin{array}{cc} 1 & 0 \\ 0 & 1 \end{array} \right) \right]\left[ \begin{array}{c} v_{11} \\ v_{21} \end{array} \right] = 0\]
puis
\[\left[ \left( \begin{array}{cc} -.8 & .8 \\ .8 & -.8 \end{array} \right) \right]\left[ \begin{array}{c} v_{11} \\ v_{21} \end{array} \right] = 0\]
\[\begin{aligned} -.8v_{11} + .8 v_{21}=0 \\ .8v_{11} - .8 v_{21}=0 \end{aligned}\]
et de la même façon pour \(\lambda = .2\) :
\[\left[ \left( \begin{array}{cc} 1 & .8 \\ .8 & 1 \end{array} \right) - .2 \left(\begin{array}{cc} 1 & 0 \\ 0 & 1 \end{array} \right) \right]\left[ \begin{array}{c} v_{11} \\ v_{21} \end{array} \right] = 0\]
se simplifie en
\[\left[ \left( \begin{array}{cc} .8 & .8 \\ .8 & .8 \end{array} \right) \right]\left[ \begin{array}{c} v_{12} \\ v_{22} \end{array} \right] = 0\]
pour donner sous forme linéaire.
\[\begin{aligned} .8v_{12} + .8 v_{22}=0\\ .8v_{12} + .8 v_{22}=0 \end{aligned}\]
Ces systèmes d’équations sont toujours indéterminés. Pour les résoudre, la solution est de fixer arbitrairement, pour chaque colonne, un des éléments de \(\mathbf{V}\), comme \(v_{11} = v_{12} = 1\).
Pour \(v_{11} = 1\), cela donne \[\begin{aligned} -.8(1)+.8v_{21} = 0\\ -.8 + .8v_{21} = 0\\ v_{21} = 1 \end{aligned}\]
et pour \(v_{12} = 1\) :
\[\begin{aligned} .8(1)+.8v_{22} = 0\\ .8+ .8v_{22} = 0\\ v_{22} = -1 \end{aligned}\]
Ainsi, la matrice \(\mathbf{V}\) est
\[\mathbf{V} = \left[ \begin{array}{cc} 1 & 1 \\ 1 & -1 \end{array} \right]\]
Il ne reste qu’à normaliser les colonnes (vecteurs) pour que leur longueur soit l’unité38. Pour ce faire, il faut diviser chaque élément du vecteur et le diviser par racine carré de la somme des carrés des éléments du vecteur.
\[ \mathbf{V_{ij}} = \frac{v_{ij}}{ \sqrt{\sum_{i = 1}^p v_{i}}} \] ce qui donne
\[ \mathbf{V} = \left[ \begin{array}{cc} .707 & .707 \\ .707 & -.707 \end{array} \right] \] Les résultats sont reproduits.
Pour un grand nombre de variables, il est préférable d’utiliser une fonction d’optimisation. La logique demeure similaire. En fixant un élément du vecteur propre, la fonction tente de trouver la meilleure solution pour résoudre l’équation (18.5). Comme ces valeurs dépendent entièrement de la valeur fixée (qui peut être n’importe quelle valeur pour n’importe quel élément du vecteur), cela justifie la normalisation à la dernière étape.
Pour ce faire, à chaque vecteur propre, la fonction reçoit la valeur propre associée, la matrice de corrélation et une série d’estimateur (le vecteur propre) à trouver.
La fonction maison cherche.vecteur() calcule la somme (sum() des écarts absolus (abs()) entre les estimateurs et la valeur cible de 0 de l’équation (18.5). La fonction R optim() prend cette fonction et tente de minimiser les distances, c’est-à-dire d’arriver au résultat de 0 en variant les estimateurs. Noter comment un estimateur est déjà fixé à 1 dans matrix(c(1, est)) qui correspond à \(v_j\) où \(v_{1j}=1\). La fonction optim() prend un argument d’estimateur par, les paramètres à trouver et fn la fonction à optimiser et une méthode d’optimisation appropriée, method = "BDGS dans ce cas-ci. Les deux autres arguments sont pour la fonction à optimiser cherche.vecteur(), soit la matrice de covariance et la valeur propre.
# Fonction à optimiser
cherche.vecteur <- function(est, Ep, M) {
# est = estimateur
# Ep = valeur propre
# M = matrice de corrélation
sum(abs((M - diag(Ep, nrow(M))) %*% matrix(c(1, est))))
}
# Variable pour enregistrer les résultats
V <- matrix(0, nrow(S), ncol(S))
# Boucle d'optimisation pour chaque
# valeur propre
for (i in 1:length(E)) {
V[,i] <- c(1, optim(par = rep(0, ncol(S)-1),
fn = cherche.vecteur,
method = "BFGS",
Ep = E[i], # valeur.prpore
M = S)$par
)
}
# Normaliser les vecteurs
V <- t(t(V) / sqrt(colSums(V^2)))Il suffit maintenant de jumeler la syntaxe pour trouver les valeurs propres et celle ci-dessus pour créer sa propre fonction d’analyse en composantes principales.
acp.maison <- function(S){
# Trouver les coefficients polynomiaux
coef.poly <- pracma::charpoly(S)
# Inverser l'ordre
coef.poly <- coef.poly[length(coef.poly):1]
# Trouver les valeurs à 0 (valeurs propres, E)
E <- Re(polyroot(coef.poly))
# Mettre en ordre décroissant
E <- sort(E, decreasing = TRUE)
# Fonction à optimiser
cherche.vecteur <- function(est, Ep, M) {
sum(abs((M - diag(Ep, nrow(S))) %*% matrix(c(1, est))))
}
# Variable pour enregistrer les vecteurs propres
V <- matrix(0, nrow(S), ncol(S))
# Boucle d'optimisation pour chaque
# valeur propre
for (i in 1:length(E)) {
V[,i] <- c(1, optim(par = rep(0, ncol(S)-1),
fn = cherche.vecteur,
method = "BFGS",
Ep = E[i],
M = S)$par
)
}
# Normaliser les vecteurs
V <- t(t(V) / sqrt(colSums(V^2)))
return(list(valeur.propre = E,
vecteur.propre = V))
}Pour terminer, la fonction est mise à l’épreuve.
acp.maison(S)
> $valeur.propre
> [1] 1.8 0.2
>
> $vecteur.propre
> [,1] [,2]
> [1,] 0.707 0.707
> [2,] 0.707 -0.707Les résultats sont virtuellement identiques.