15 Créer
Dans le chapitre sur la régression, les variables indépendantes sont créées simultanément à partir d’une matrice de corrélation, puis des coefficients de régressions sont utilisés pour créer la variable dépendante. Dans un modèle plus élaboré, plutôt que d’ignorer ces corrélations, les liens entre les variables prédictrices peuvent être explicitement modélisés. Cela revient à décrire un modèle de façon à ce qu’une première variable cause la seconde; la première et la seconde causent la troisième et ainsi de suite.
La modélisation en système d’équations devient primordiale dans les prochaines sections, notamment pour les analyses de trajectoires, de médiation, de modération, et plus. C’est le fondement de la modélisation par équations structurelles (SEM).
Dans ce chapitre19, des techniques de modélisation avancées sont présentées. Elles s’appliquent à des modèles de trajectoires récursifs, c’est-à-dire que la causalité s’enchaîne dans une direction, de la première variable vers la dernière20.
15.1 La loi de la somme des variances
La loi de la somme des variances postule comment additionner la variance de variables aléatoires, quelle que soit leur distribution (Casella & Berger, 2002). Le cas le plus simple est celui de deux variables aléatoires, comme \(x_1\) et \(x_2\), et la façon dont elles s’additionnent pour former une troisième variable, \(y\). Elles donnent un modèle simple représenté par l’équation (15.1).
\[\begin{equation} y=x_1+x_2 \tag{15.1} \end{equation}\]
La variance de leur somme prend la forme suivante \[\begin{equation} \sigma_y^2=\sigma_{x_1}^2+\sigma_{x_2}^2 \tag{15.2} \end{equation}\]
où \(\sigma^2\) est le symbole habituel de la variance. La variance de la somme (ou de la différence) de deux variables indépendantes (non corrélées) aléatoires est leur somme. En fait, la somme de \(p\) variables indépendantes est la somme de leurs variances. En syntaxe R, ces équations ressemblent à ceci.
set.seed(1155) # reproductibilité
n <- 100000 # taille élevée pour la précision
s.x1 <- sqrt(2) # variance de 2
s.x2 <- sqrt(3) # variance de 3
# Création des variables
x1 <- rnorm(n = n, sd = s.x1)
x2 <- rnorm(n = n, sd = s.x2) Dans cet exemple, les variances de x1 et de x3 sont égales à 2 et 3 respectivement. Si ces deux variables sont additionnées pour créer y, alors, selon l’équation (15.2), la variance de y est de \(\sigma^2_{y}=\sigma^2_{x_{1}} + \sigma^2_{x_2} = 2 + 3= 5\)
Le résultat concorde.
En pratique, il est rare que les variables prédictrices soient non corrélées. Ici, aucune corrélation n’a été précisée entre x1 et x2. Pour développer le cas général afin d’inclure la covariance entre \(x_1\) et \(x_2\), représentée par \(\sigma_{x_1,x_2}\), alors la loi de la somme des variances devient ceci.
\[\begin{equation} \sigma_y^2=\sigma_{x_1}^2+\sigma_{x_2}^2+2\sigma_{x_1,x_2} \tag{15.3} \end{equation}\]
L’équation (15.2) est un cas particulier lorsque la covariance entre x1 et x2 est nulle, \(\sigma_{x_1 x_2}=0\). En syntaxe R, pour \(\rho = .5\), cela revient à programmer la syntaxe suivante.
# Création de variables corrélées
rho <- .5 # corrélation de .5
s.x1x2 <- rho * s.x1 * s.x2 # covariance de x et y
S <- matrix(c(s.x1^2, s.x1x2, # matrice de covariance
s.x1x2, s.x2^2), ncol = 2, nrow = 2)
# Création de variables
X <- MASS::mvrnorm(n = n, Sigma = S, mu = c(0, 0), empirical = TRUE)
x1 <- X[,1] ; x2 <- X[,2]
# La somme de deux variables corrélées
y <- x1 + x2
var(y)
> [1] 7.45
# Vérifier par
s.x1^2 + s.x2^2 + 2 * s.x1x2
> [1] 7.45Pour rappel, la corrélation s’obtient avec \(\rho_{x_1,x_2}=\sigma_{x_1,x_2}/(\sigma_{x_1} \sigma_{x_2})\) et inversement la covariance est obtenue par \(\rho_{x_1,x_2} \sigma_{x_1} \sigma_{x_2}=\sigma_{x_1,x_2}\). En calculant d’abord la covariance
\[\sigma_{x_1,x_2} = \rho_{x_1,x_2} \sigma_{x_1} \sigma_{x_2} = 0.5 \times 1.414 \times 1.732 = 1.225,\]
confirmée par R,
l’équation (15.3) pour la variance de y mène à
\[\sigma_y^2=\sigma_{x_1}^2+\sigma_{x_2}^2+2\sigma_{x_1,x_2}= 2+3 + 2 \times 1.225 = 7.449,\] ce qui est très près du résultat simulé.
La loi des sommes des variances est directement reliée au théorème de Pythagore tel qu’illustré par l’équation (15.2). Deux variables non corrélées peuvent être envisagées comme formant un triangle rectangle. Son extension est le règle du cosinus, soit l’équation (15.3). Il s’agit de la généralisation du théorème de Pythagore pour les triangles non rectangulaires, de sorte que la corrélation représente géométriquement un angle (Rodgers & Nicewander, 1988).
La Figure 15.1 montre un triangle rectangle dont l’hypoténuse représente l’écart type de la somme de deux variables indépendantes. Lorsque l’angle est à 90\(^\circ\), la corrélation est nulle. Il suffit de mettre les droites au carré pour retrouver l’équation (15.2). Lorsque l’angle rétréci, plus les deux lignes \(\sigma\) se rapprochent et projettent sur une plus longue distance la somme des variances. Lorsqu’elles sont collées l’une sur l’autre, la corrélation est parfaite.
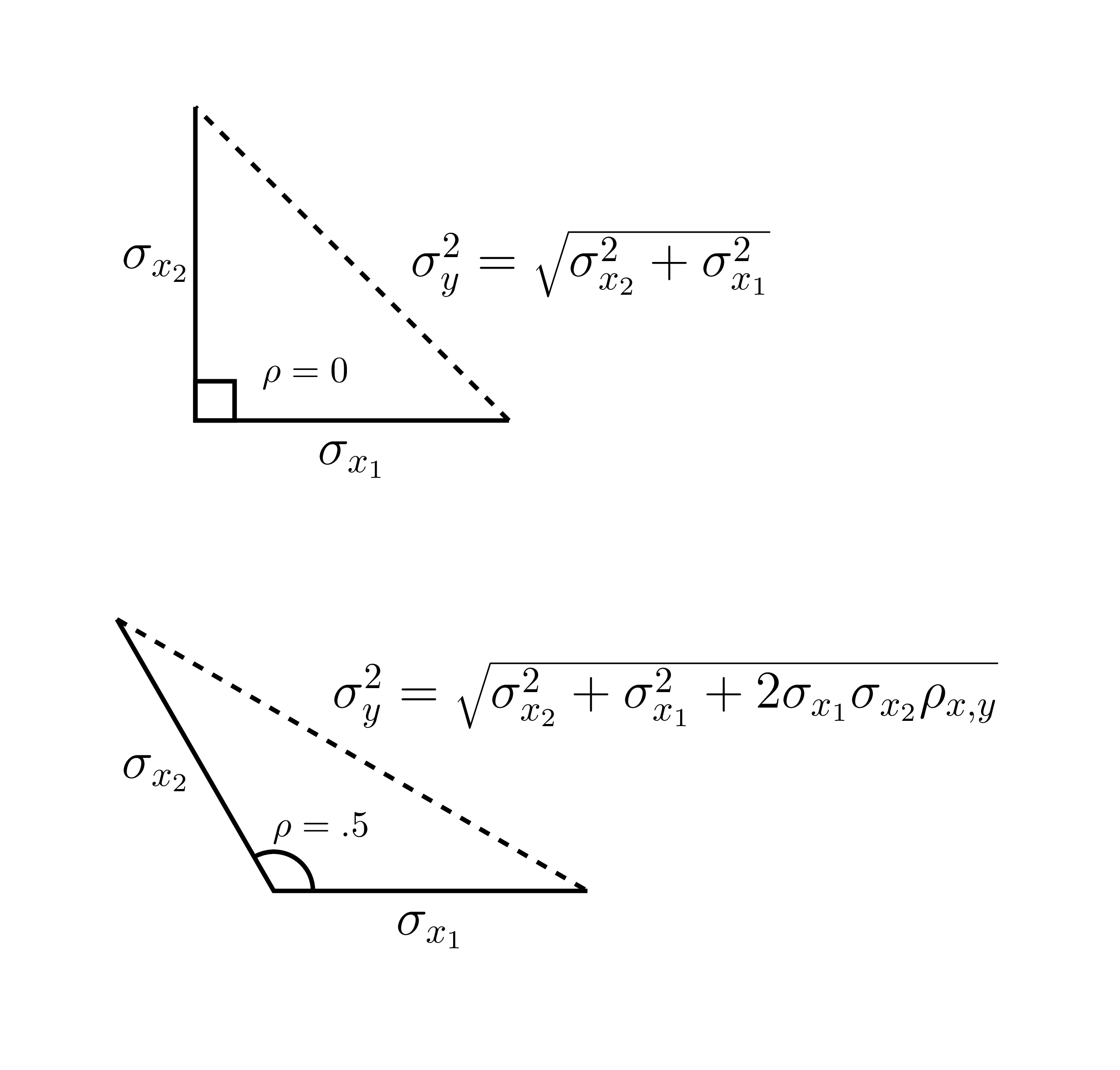
Figure 15.1: Représentation des variables sous forme de triangles.
Une autre façon mathématiquement plus simple de calculer la loi de la somme des variances est de concevoir la variance de la somme de \(p\) variables comme la grande somme de leur matrice de covariance. La grande somme est une fonction mathématique informelle qui fait référence à la somme de tous les éléments d’une matrice. Soit \(\mathbf{\Sigma}\) (Sigma), la matrice de variance-covariance de deux variables aléatoires \(x_1\) et \(x_2\) (les éléments diagonaux sont des variances), alors
\[\begin{equation} \sigma_y^2 = \text{grande somme}(\mathbf{\Sigma}) = \text{grande somme}\left(\begin{array}{cc} \sigma_{x_1}^2 & \sigma_{x_1,x_2} \\ \sigma_{x_1,x_2} & \sigma_{x_2}^2 \end{array}\right) \tag{15.4} \end{equation}\]
ce qui, en faisant la somme, conduit à l’équation (15.3). Encore une fois, si \(\sigma_{x_1,x_2}=0\), alors l’équation (15.4) est égale à l’équation (15.2). Cette formulation a l’avantage de montrer l’origine des deux covariances dans l’équation (15.3). La syntaxe est plus rudimentaire en code R.
Même si la notation matricielle peut sembler peu attrayante au départ, elle devient beaucoup plus intéressante lorsque le nombre de variables, \(p\), augmente, car il y a \(p(p-1)/2\) éléments hors diagonale à ajouter aux \(p\) variances. Elle deviendra même indispensable à la fin de ce chapitre.
Pour un exemple à \(p=3\), l’équation (15.4) devient ceci.
\[\begin{equation} \sigma_y^2=\text{grande somme}(\mathbf{\Sigma})=\text{grande somme} \left(\begin{array}{ccc} \sigma_{x_1}^2&\sigma_{x_1,x_2}&\sigma_{x_1 x_3} \\ \sigma_{x_1,x_2}&\sigma_{x_2}^2&\sigma_{x_2 x_3}\\ \sigma_{x_1 x_3}&\sigma_{x_2 x_3}&\sigma_{x_3}^2 \end{array} \right) \tag{15.5} \end{equation}\]
Sous la forme linéaire, l’équation (15.5) devient
\[\begin{equation} \sigma_y^2=\sigma_{x_1}^2+\sigma_{x_2}^2+\sigma_{x_3}^2+2\sigma_{x_1,x_2}+2\sigma_{x_1 x_3}+2\sigma_{x_2 x_3} \tag{15.6} \end{equation}\]
et s’allonge à mesure que \(p\) s’accroît.
Une opération matricielle équivalente à la grande somme est
\[\begin{equation} \mathbf{1}^{\prime} \mathbf{\Sigma} \mathbf{1} \tag{15.7} \end{equation}\]
où \(1\) est un vecteur de longueur \(p\) contenant seulement des 1. Voici en syntaxe R.
Cette opération produit la somme de tous les éléments de \(\mathbf{\Sigma}\). Cela sera utile pour dériver un cas plus général dans la section suivante.
15.1.1 L’ajout des constantes d’échelle \(\beta\)
Les équations (15.3), (15.4), (15.5) et (15.6) sont des cas particuliers d’une loi plus générale. Elles sont inadéquates si des constantes d’échelle (scaling constant) sont ajoutées (qui seront plus tard des coefficients de régression) ou pour calculer la différence (un type d’échelle également).
La situation où la variable \(y\) correspond au produit d’une constante \(\beta\) et de la variable \(x\) comme :
\[\begin{equation} y=\beta x \tag{15.8} \end{equation}\]
un modèle linéaire qui ne comporte pas d’erreur (\(\epsilon\) est ignoré pour l’instant).
Il peut être utile de considérer \(\beta\) comme le degré de relation entre deux variances, mais aussi comme un pur modificateur de l’écart type (également une constante d’échelle). De la même manière, une variable aléatoire avec une moyenne de \(0\) et un écart type de \(1\), \(x\sim \mathcal{N}(0,1)\), multipliée par la valeur \(\beta\), un facteur d’échelle arbitraire, est distribuée comme \(\beta x \sim \mathcal{N}(0,\beta)\). Ainsi, \(\beta\) a modifié (ou mis à l’échelle) l’écart type de la distribution. Un cas connexe et fréquemment rencontré est lorsque les données sont standardisées en tant que score-\(z\) ou non standardisées (respectivement, divisées ou multipliées par \(\sigma\)). La contribution est un écart-type, donc \(\beta\) doit être élevé au carré pour donner la variance de \(y\), soit \(\beta^2\). Cela mène à l’équation (15.9) qui permet le calcul de la variance de \(y\).
\[\begin{equation} \sigma_y^2=\beta^2 \sigma_x^2 \tag{15.9} \end{equation}\]
En termes de syntaxe R, cela se traduit (toujours avec le même exemple).
beta <- 4
# La variance de x1 est toujours de 2
y <- beta * x1
var(y)
> [1] 32
# Vérifier par
beta^2 * s.x1^2
> [1] 32L’équation (15.9) donne \(\sigma_y^2=\beta^2 \sigma_x^2=4^2 \times 2= 32\), ce qui est identique.
L’étape suivante consiste à considérer un modèle avec deux variables et deux constantes d’échelles, ce qui rappelle de plus en plus la régression. Le modèle linéaire prend la forme suivante :
\[\begin{equation} y=\beta_1 x_1+\beta_2 x_2. \tag{15.10} \end{equation}\]
Cette équation correspond au même modèle que l’équation (15.1) où les constantes d’échelle \(\beta_i\) sont ajoutées. Pour considérer les constantes d’échelle, la loi de la somme des variances, basée sur l’équation (15.2), devient pour deux variables indépendantes :
\[ \sigma_y^2=\beta_1^2 \sigma_{x_1}^2+\beta_2^2 \sigma_{x_2}^2. \]
Quand les variables covarient, comme l’équation (15.3), cela devient :
\[\begin{equation} \sigma_y^2=\beta_1^2 \sigma_{x_1}^2+\beta_2^2 \sigma_{x_2}^2+2\beta_1 \beta_2 \sigma_{x_1,x_2}. \tag{15.11} \end{equation}\]
Dans ces équations, les \(\beta_i\) mettent à l’échelle la variance et la covariance. Ces équations se vérifient avec R (toujours avec le même exemple).
# En suivant, l'exemple précédent
beta1 <- 4
beta2 <- 5
y <- beta1 * x1 + beta2 * x2
var(y)
> [1] 156
# Vérifier par
beta1^2 * s.x1^2 + beta2^2 * s.x2^2 +
2 * beta1 * beta2 * s.x1x2
> [1] 156Le résultat est celui attendu par l’équation (15.12).
\[ \begin{aligned} \sigma_y^2 &= \beta_1^2 \sigma_{x_1}^2+\beta_2^2 \sigma_{x_2}^2+2\beta_1 \beta_2 \sigma_{x_1,x_2} \\ & = 4^2 \times 2 + 5^2 \times 3 + 2 \times 4 \times 5 \times 1.225 \\ & = 155.99 \end{aligned} \]
Comme vue précédemment, la formule en termes d’algèbre matricielle est plus simple et plus élégante, soit
\[\begin{equation} \sigma_y^2 = \mathbf{B}^{\prime} \mathbf{\Sigma} \mathbf{B} \tag{15.12} \end{equation}\]
où \(\mathbf{B}\) (\(\beta\) majuscule) est un vecteur contenant tous les coefficients de régression \(\beta_i\) de longueur \(p\) prédisant \(y\) et s’appliquant à un nombre quelconque de prédicteurs \(x\). Le premier \(\prime\) est le symbole de transposition, un opérateur qui pivote la matrice sur sa diagonale et, dans le cas d’un vecteur, retourne les colonnes en lignes et vice-versa (voir son implication dans l’équation (15.13) par exemple). Dans l’équation (15.12), les deux vecteurs \(\mathbf{B}\) revient à élever au carré \(\beta_i\). Si tous les éléments de \(\mathbf{B}\) égalent 1, alors l’équation (15.12) est identique à la définition d’une grande somme, voir l’équation (15.7). En syntaxe R, l’équation (15.12) donne :
# Joint beta1 et beta2 dans un vecteur
beta <- c(beta1, beta2)
# S est la matrice de covariance calculée auparavant.
t(beta) %*% S %*% beta
> [,1]
> [1,] 156un code plus général et qui s’appliquera à toutes les situations (peu importe la valeur de \(p\), le nombre de variables). La fonction t() correspond à la transposeition, soit le symbole \(^\prime\) de l’équation (15.12)21.
Il est intéressant de noter que l’équation (15.12) est la même que les coefficients de détermination, \(R^2\) (Cohen et al., 2003), lorsque toutes les variables et les coefficients de régression sont standardisés.
Dans le modèle linéaire simple décrit dans l’équation (15.10), l’équation (15.11) devient
\[\begin{equation} \sigma_y^2 = \left(\begin{array}{cc} \beta_1 & \beta_2 \end{array}\right) \left( \begin{array}{cc} \sigma^2_{x_1} & \sigma_{x_1,x_2} \\ \sigma_{x_2,x_1} & \sigma^2_{x_2} \end{array} \right) \left(\begin{array}{c} \beta_1 \\ \beta_2 \end{array} \right) \tag{15.13} \end{equation}\]
ce qui est équivalent à l’équation (15.11). À ce stade, le lecteur peut avoir l’intuition que les équations (15.1) à (15.6) n’étaient qu’un cas particulier où tous les \(\beta=1\).
15.1.2 La différence de variances
La variance de la différence de deux variables revient à affirmer que le \(\beta\) des variables soustraites est de signe inverse (s’il est négatif, il devient positif ou s’il est positif, il devient négatif). En d’autres termes, la constante d’échelle est négative, c’est-à-dire \(-\beta\), ce qui conduit à
\[ y=\beta_1 x_1-\beta_2 x_2 \]
ou, de manière équivalente
\[ y=(\beta_1) x_1+(-\beta_2) x_2 \]
donnent
\[\begin{equation} \begin{aligned} \sigma_y^2 &= \left(\begin{array}{cc} \beta_1 & -\beta_2 \end{array}\right) \left( \begin{array}{cc} \sigma^2_{x_1} & \sigma_{x_1,x_2} \\ \sigma_{x_2,x_1} & \sigma^2_{x_2} \end{array} \right) \left(\begin{array}{c} \beta_1 \\ -\beta_2 \end{array} \right) \\[15pt] & = \beta_1^2 \sigma_{x_1}^2+(-\beta_2)^2 \sigma^2_{x_2} + 2(\beta_1)(-\beta_2)\sigma_{x_1,x_2} \\[15pt] & = \beta_1^2 \sigma_{x_1}^2+\beta_2^2 \sigma^2_{x_2} - 2\beta_1\beta_2\sigma_{x_1,x_2} \end{aligned} \tag{15.14} \end{equation}\]
Comme prévu, la variance de la différence de deux variables aléatoires est la somme de leurs variances en soustrayant deux fois leur échelle de covariance par \(\beta\). Cela se vérifie avec R.
15.2 Les implications pour la modélisation
La loi de la somme des variances a de nombreuses implications pour la modélisation, en particulier lorsque les données sont façonnées selon certaines caractéristiques souhaitables, comme c’est le cas pour les modèles linéaires. La régression linéaire est une approche permettant de modéliser des effets additifs (variables indépendantes, \(x_i\)) afin de prédire une variable dépendante (\(y\)). La linéarité fait référence à la propriété d’une fonction d’être compatible avec l’addition et la mise à l’échelle. En tant que tel, il existe une relation directe entre les équations ci-dessus et le modèle linéaire :
\[\begin{equation} y=\beta_1 x_1 + ... +\beta_p x_p+\epsilon. \tag{15.15} \end{equation}\]
L’équation (15.15) est la forme générale du modèle linéaire de l’équation (15.1) et (15.9) dans laquelle la variance de \(y\) est une fonction des variances-covariances des \(x\) pondérées par \(\beta\). En fait, l’équation (15.15) est le modèle linéaire général sauf qu’elle omet 1) la constante \(\beta_0\) qui ne joue aucun rôle dans la variance de la variable dépendante, et 2) en ajoute l’erreur (\(\epsilon\)), une variable indépendante non corrélée \(x\), avec une moyenne de \(0\), un écart-type \(\sigma_\epsilon\).
15.2.1 Le calcul de la variance de l’erreur
Le modèle linéaire le plus simple, soit à deux variables est représentée par l’équation suivante
\[\begin{equation} y=x+\epsilon \tag{15.16} \end{equation}\]
où \(\epsilon\) est le terme d’erreur résiduel. C’est le minimum pour construire un modèle bivarié. Il s’agit de la même somme bivariée que l’équation (15.1), mais, dans cette instance, \(x_2\) est remplacé par \(\epsilon\) et est défini comme indépendant de \(x_1\) (non corrélé). Sur la base de ce modèle, l’équation (15.2) conduit à l’équation suivante.
\[ \sigma_y^2=\sigma_x^2+\sigma_\epsilon^2 \]
Dans la plupart des cas de modélisation de données, les variances \(\sigma_x^2\) et \(\sigma_y^2\) sont généralement spécifiées à l’avance plutôt que \(\sigma_\epsilon^2\). Le calcul a priori de la variance de l’erreur est plus pertinent que d’ajuster les paramètres d’intérêt. En réarrangeant l’équation (15.16) pour isoler \(\epsilon\),
\[ \epsilon=y-x \]
et en termes de variance
\[ \sigma_\epsilon^2=\sigma_y^2+\sigma_x^2-2\sigma_{x,y} \]
où l’équation (15.14) pour la forme en algèbre matricielle.
\[ \sigma_{\epsilon}^2 = \left(\begin{array}{cc} 1 & -1 \end{array}\right) \left( \begin{array}{cc} \sigma^2_{y} & \sigma_{x,y} \\ \sigma_{x,y} & \sigma^2_{x} \end{array} \right) \left(\begin{array}{c} 1 \\ -1 \end{array} \right) = \sigma^2_y + \sigma^2_x - 2\sigma_{x,y} \]
15.2.2 La variance des erreurs avec \(\beta\)
Une préoccupation lors de la modélisation des données est la préservation les propriétés souhaitées d’un modèle dans les jeux de données telle que la variance de l’erreur, les paramètres de régression, les covariances, etc. Après la variance du terme d’erreur, le dernier élément à considérer correspond aux coefficients de régression, \(\beta\), soit le degré de la relation entre les variables indépendantes et la variable dépendante. À partir de l’équation (15.16), on ajoute la pente et l’erreur :
\[ y=\beta x+\epsilon \]
La loi de la somme des variances pour ce modèle devient
\[\begin{equation} \sigma_y^2=\beta^2 \sigma_x^2+\sigma_\epsilon^2 \tag{15.17} \end{equation}\]
Pour rappel, l’erreur n’est pas corrélée à la variable indépendante \(x_i\). Comme précédemment, la forme d’algèbre matricielle est plus simple et plus élégante :
\[\begin{equation} \sigma_y^2 = \mathbf{B}^{\prime} \mathbf{\Sigma} \mathbf{B} + \sigma_\epsilon^2 \tag{15.18} \end{equation}\]
où \(\beta\) est un vecteur contenant tous les coefficients de régression \(\beta\) prédisant \(y\) et s’appliquant à un nombre quelconque de prédicteurs \(x\). En profitant de l’indépendance du terme d’erreur, l’équation (15.18) est réarrangée comme :
\[\begin{equation} \sigma_\epsilon^2=\sigma_y^2 -\mathbf{B}^{\prime} \mathbf{\Sigma} \mathbf{B} \tag{15.19} \end{equation}\]
ce qui donne la variance du terme d’erreur. Sous une forme linéaire (pour une seule variable indépendante), il est possible de réarranger l’équation (15.17) pour isoler \(\sigma_\epsilon\).
\[ \sigma_\epsilon^2=\sigma_y^2-\beta^2 \sigma_x^2 \]
15.2.3 Le scénario standardisé
Pour conclure cette section, le scénario standardisé, c’est-à-dire le scénario où les variances des variables sont égales à \(1\). Plus précisément, la variance de chaque variable est fixe ; seules les erreurs résiduelles doivent être ajustées pour maintenir ces propriétés. Dans ce scénario, la matrice de variance-covariance, \(\Sigma\), est une matrice de corrélation, qui définit les variances des erreurs résiduelles. Pour calculer la variance des résidus, l’équation (15.19) est utilisée en remplaçant la variance des variables par \(1\) comme suit :
\[\begin{equation} \sigma_\epsilon^2=1 - \mathbf{B}^{\prime} \mathbf{\Sigma} \mathbf{B} \tag{15.20} \end{equation}\]
ou, pour un seul prédicteur.
\[\begin{equation} \sigma_\epsilon^2=1-\beta^2 \sigma_x^2 \tag{15.21} \end{equation}\]
Comme mentionner pour l’équation (15.12), ces deux dernières équations rappellent le coefficient de détermination. La valeur \(1\) correspond au potentiel explicatif d’une variable, \(\sigma_\epsilon^2\) est la variance résiduelle et, par conséquent, \(1-\sigma_\epsilon^2\) est la variance expliquée par le modèle.
15.2.4 Le scénario non standardisé
Dans la pratique, les scénarios sont rarement standardisés. Les variables n’ont pas toutes des variances de \(1\) et des moyennes de \(0\). Pour ajouter une touche de naturelle aux jeux de données, il est possible, une fois que le système d’équations est complètement obtenu, d’ajouter des variances différentes en multipliant une variable par l’écart-type souhaité et d’additionner une moyenne. Cela modifiera la matrice de covariance et les coefficients de régression, mais la force relative des liens et la matrice de corrélation resteront identiques. En d’autres termes, la déstandardisation est l’inverse d’un score \(z\). Les données créées jusqu’ici sont des scores \(z\) et pour les déstandardisés, il faut procéder ainsi \(x = s(z + \bar{x})\), où \(s\) est l’écart-type et \(\bar{x}\) est la moyenne de la variable déstandardisée.
15.3 La création de modèle récursif
Jusqu’à présent, seule la création d’une variable a été présentée. Le défi lors de la création d’un système d’équations est d’obtenir la matrice de covariance des variables précédentes pour chaque variable subséquente.
Puisque le sujet peut devenir rapidement compliqué, cette section est basée sur un exemple à trois variables avec un scénario standardisé (variables centrées et réduites). Le cas général sera développé par la suite.
15.3.1 Le cas spécifique
Le défi débute lorsqu’il y a trois variables ou plus à générer. Toutefois, le cas à trois variables est tout de même abordable. Un élément crucial à garder en perspective est l’unidirectionalité de la causalité, c’est-à-dire qu’une variable doit aller dans un seul sens (d’un variable à l’autre) sans créer de boucle. Cela se nomme un modèle récursif, impliquant du même coup l’existence de modèles non-récursifs. Une caractéristique des modèles non-récursifs est d’avoir une ou des boucles de causalité bidirectionnelle, comme \(x \leftrightarrow y\), alors que les modèles récursif n’ont que des causalité directionnel comme \(x \rightarrow y\). Les modèles non-récursifs dépassent largement la portée de cet chapitre.
Pour un modèle à trois variables, une seule configuration récursive complète est possible. Elle est présentée à la Figure 15.2.
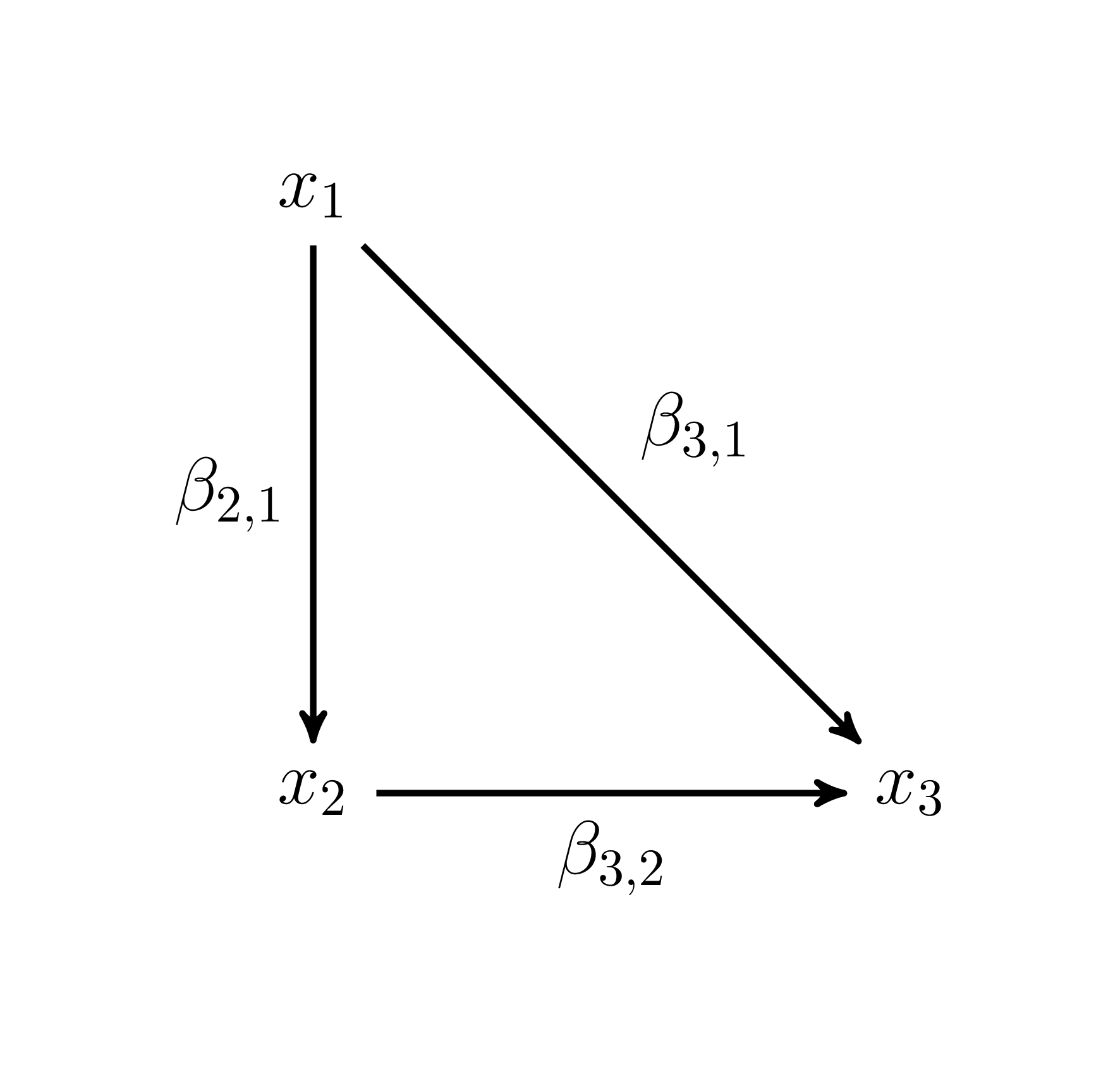
Figure 15.2: Modèle à trois variables.
La Figure 15.2 montre un modèle à trois variables. La première variable \(x_1\) prédit \(x_2\) et \(x_3\), en plus \(x_2\) prédit \(x_3\). Ce modèle peut aussi se représenter par la matrice \(\mathbf{B}\) dans laquelle se retrouvent les coefficients de régression qui relient les variables. Dans ce cas-ci, \(\beta_{3,1}\) signifie que la variable 1 prédit la 3 à un degré \(\beta_{3,1}\); \(\beta_{3,2}\) signifie que la variable 2 prédit la 3 à un degré \(\beta_{3,2}\). Le premier indice correspond à l’effet (variable dépendante) et le deuxième à la cause (variable indépendante).
\[\begin{equation} \mathbf{B} = \left( \begin{array}{ccc} 0 & 0 & 0 \\ \beta_{2,1} & 0 & 0 \\ \beta_{3,1} & \beta_{3,2} & 0 \\ \end{array} \right) \tag{15.22} \end{equation}\]
Afin de bâtir un exemple complet avec R, la syntaxe ci-dessous montre les paramètres arbitraires pour la création de données à partir du modèle de la Figure 15.2.
# Pour la reproductibilité
set.seed(1448)
n <- 100000
# Paramètres arbitraires
beta21 <- .2
beta31 <- .4
beta32 <- -.5La première variable \(x_1\) est exogène, c’est-à-dire qu’elle n’est pas prédite par aucune autre variable, et n’obtient aucune information de d’autres variables. Cela se perçoit notamment dans la matrice \(\mathbf{B}\) avec la première ligne ne contenant que des 0. Pour créer x1, il suffit de connaître sa variance (1 dans un scénario standardisé). Il faudra en supplément un vecteur de variances (ici, toutes fixées à 1 par le scénario standardisé).
# Création de la première variable
x1 <- rnorm(n = n, sd = 1) # Variance de 1À l’aide de la loi de la somme des variances, la création de \(x_2\) est assez simple puisqu’il n’y a qu’un seul prédicteur.
\[ x_2 = \beta_{2,1}x_1+\epsilon_{x_2} \]
En suivant l’équation (15.21), il est possible de calculer la variance résiduelle, toujours en assumant que \(\sigma^2_{x_1} = \sigma^2_{x_2}=1\).
\[ \sigma^2_{\epsilon_{x_2}} = 1-\beta_{2,1}^2\sigma^2_{x_1}=1-\beta_{21}^2 \]
En code R, il est possible de procéder ainsi.
# Variance résiduelle
e_x2 <- 1 - beta21^2
# Création de la variable
x2 = beta21 * x1 + rnorm(n = n, sd = sqrt(e_x2)) # Variance de 1Maintenant, il reste à créer la variable \(x_3\). Celle-ci est générée à partir de \(x_1\) et \(x_2\) selon l’équation suivante :
\[ x_3 = \beta_{3,1}x_1 + \beta_{3,2}x_2 + \epsilon_{x_3}. \]
La variance résiduelle suit l’équation (15.20). En équation linéaire, elle s’écrit comme suit :
\[ \begin{aligned} \sigma^2_{\epsilon_{x_3}} & = \sigma^2_{x_3} -( \beta_{3,1}^2\sigma^2_{x_1} + \beta_{3,2}^2\sigma^2_{x_2} + 2\beta_{3,1}\beta_{3,2}\sigma_{x_1,x_2}) \\ & = 1-(\beta_{3,1}^2+\beta_{3,2}^2 + 2\beta_{3,1}\beta_{3,2}\sigma_{x_1,x_2}) \end{aligned}. \]
Elle occasionne toutefois un défi, car la covariance entre \(x_1\) et \(x_2\) n’est pas explicitement connue. Dans le cas d’une variable prédite exclusivement par une autre variable, qui elle est exogène (sans prédicteur), leur covariance est égale au coefficient de régression, soit \(\beta_{21}\). Ce cas ne survient que dans cette situation précise. Il sera impératif de dégager une solution générale pour des modèles ayant plus de trois variables, la complexité du calcul de la covariance augmentant avec la croissance de \(p\). En R, \(x_3\) se génère ainsi.
# Variance résiduelle
e_x3 <- 1 - (beta31^2 + beta32^2 +
2 * beta31 * beta32 * beta21)
# Création de la variable
x3 = beta31 * x1 + beta32 *
x2 + rnorm(n = n, sd = sqrt(e_x3))Il est possible de vérifier les caractéristiques des trois modèles.
# Création du jeu de données
X <- data.frame(x1 = x1,
x2 = x2,
x3 = x3)
# Comme il s'agit d'un scénario standardisé, la matrice de
# corrélation est similaire à la matrice de covariance.
cov(X)
> x1 x2 x3
> x1 1.002 0.202 0.303
> x2 0.202 1.004 -0.418
> x3 0.303 -0.418 0.997
cor(X)
> x1 x2 x3
> x1 1.000 0.201 0.303
> x2 0.201 1.000 -0.417
> x3 0.303 -0.417 1.000
# Retrouver beta21
lm(x2 ~ x1, data = X)
>
> Call:
> lm(formula = x2 ~ x1, data = X)
>
> Coefficients:
> (Intercept) x1
> 0.00148 0.20113
# Retrouver beta31 et beta32
lm(x3 ~ x1 + x2, data = X)
>
> Call:
> lm(formula = x3 ~ x1 + x2, data = X)
>
> Coefficients:
> (Intercept) x1 x2
> 0.00578 0.40254 -0.49663Comme il s’agit d’un scénario standardisé, la matrice de corrélation est similaire à la matrice de covariance. Notamment, les variances sont près de \(1\). De plus, les résultats confirment que la covariance entre \(x_1\) et \(x_2\) est bel et bien le coefficient de régression, mais surtout qu’il s’agit du seul cas où cela est vrai. Les régressions effectuées par lm() retrouvent également les \(\beta\) choisis pour l’exemple.
15.3.2 Le cas général
Un cas général permet d’obtenir la matrice de covariance \(\mathbf{\Sigma}\) à partir de la matrice \(\mathbf{B}\) et d’un vecteur de variance \(\text{diag}(\mathbf{\Sigma})\). Par la suite, il est possible de créer des variables en série comme mentionnée dans la section précédente, ou bien de revenir à ce qui se faisait dans les chapitres précédents, c’est-à-dire d’utiliser MASS:mvrnorm() pour générer des données.
Pour obtenir la matrice de covariance, il est nécessaire d’avoir une matrice de coefficients de régression
\[\begin{equation} \mathbf{B} = \left( \begin{array}{cccc} 0 & 0 & 0 & 0\\ \beta_{2,1} & 0 & 0 & 0\\ ...& ... & 0 & 0 \\ \beta_{p,1} & ... & \beta_{p,p-1} & 0 \end{array} \right) \tag{15.23} \end{equation}\]
et d’un vecteur de variances
\[\begin{equation} \text{diag}(\mathbf{\Sigma}) = \left(\sigma^2_{x_1},...,\sigma^2_{x_p} \right) \end{equation}\]
Ces matrices sont construites de façon générale. La matrice \(\mathbf{B}\) est de dimension \(p \times p\) avec des valeurs nulles comme triangle supérieur, incluant la diagonale. Les coefficients de régresison se trouvent dans le triangle extérieur. Le vecteur de variance contient \(p\) valeurs qui représentent les variances de variables. Elles sont toutes à l’unité (\(1\)) quand le scénario est standardisé.
L’idée sous-jacente est qu’il est possible de calculer les covariances de la \(i\)e variable à partir de la matrice de covariance des \(1:(i-1)\) variables précédentes et de leur coefficients de régression. Mathématiquement, il s’agit, respectivement de \(\mathbf{\Sigma}_{1:(i-1),1:(i-1)}\) et de \(\mathbf{B}_{i, 1:(i-1)}\). Il faut procéder en série à partir de la \(2\)e variable (toutes les variables ayant au moins un prédicteur, donc toutes sauf la première) jusqu’à la dernière \(p\) variable, \(i = 2,3,...,p\). Le calcul est décrit à l’équation (15.24), malheureusement pour certain, elle recourt à l’algèbre matricielle, mais demeure toujours beaucoup plus simple et générale que si elle était présentée en algèbre linéaire.
\[\begin{equation} \begin{aligned} \mathbf{\Sigma}_{i,1:(i-1)} = \mathbf{B}_{i+1,1:i}\mathbf{\Sigma}_{1:i,1:i}\\ \mathbf{\Sigma}_{1:(i-1),i} = \mathbf{B}_{i+1,1:i}\mathbf{\Sigma}_{1:i,1:i} \end{aligned} \tag{15.24} \end{equation}\]
Il faut à chaque étape s’assurer de faire le remplacement des valeurs obtenues sur chaque côté de la diagonale, ce qui explique pourquoi deux équations sont reproduites à l’équation (15.24) avec des indices différents pour \(\mathbf{\Sigma}\).
# Matrice B
# Rappel : beta21 <- .2; beta31 <- .4; beta32 <- -.5
B <- matrix(c( 0, 0, 0,
beta21, 0, 0,
beta31, beta32, 0),
ncol = 3, nrow = 3, byrow = TRUE)
# Vecteur de variances
V = c(1, 1, 1)
# Montrer la matrice B
B
> [,1] [,2] [,3]
> [1,] 0.0 0.0 0
> [2,] 0.2 0.0 0
> [3,] 0.4 -0.5 0Voici, pour l’exemple précédent, les étapes de calcul de l’équation (15.24) décrites une à une. D’abord, il faut construire une matrice, \(\mathbf{\Sigma}\) (S en code R) avec comme diagonale les variances. Puis, calculer l’équation (15.24). Ensuite, il faut remplacer le résultat obtenu des deux côtés de la diagonale de façon à ce que S demeure symétrique. Ces étapes sont répétées pour \(i=2,...,p\) (dans cet exemple, \(p=3\)).
# Créer une matrice de covariance préliminaire
S <- diag(V)
# Aucune covariance n'est inscrite dans S
S
> [,1] [,2] [,3]
> [1,] 1 0 0
> [2,] 0 1 0
> [3,] 0 0 1
# Première étape
i <- 2
# Calcul de la covariance entre x1 et x2
B[i, 1:(i-1)] %*% S[1:(i-1),1:(i-1)]
> [,1]
> [1,] 0.2
# Calcul de la covariance entre x1 et x2 assignée à COV
COV <- B[i, 1:(i-1)] %*% S[1:(i-1),1:(i-1)]
S[i, 1:(i-1)] <- COV
# Il faut remplacer ce résultat de chaque côté de la diagonale
S[1:(i-1),i] <- COV
# La matrice est mise à jour pour i = 2
S
> [,1] [,2] [,3]
> [1,] 1.0 0.2 0
> [2,] 0.2 1.0 0
> [3,] 0.0 0.0 1
# Pour la seconde étape, l'équation est reprise pour i = 3
i <- 3
# Calcul de la covariance entre x1 et x2 assignée à COV
COV <- B[i, 1:(i-1)] %*% S[1:(i-1), 1:(i-1)]
S[i, 1:(i-1)] = COV
S[1:(i-1), i] = COV
# La matrice est mise à jour pour i = 3
S
> [,1] [,2] [,3]
> [1,] 1.0 0.20 0.30
> [2,] 0.2 1.00 -0.42
> [3,] 0.3 -0.42 1.00
# Elle est approximativement identique
# aux données de l'exemple précédent
cov(X)
> x1 x2 x3
> x1 1.002 0.202 0.303
> x2 0.202 1.004 -0.418
> x3 0.303 -0.418 0.997Avant de continuer, une courte digression s’impose sur une méthode plus compacte, mais syntaxiquement plus compliqué pour la réassignation des valeurs dans S. Le code est présenté dans la syntaxe ci-dessous. Il appert qu’il n’est pas aussi intéressant à programmer pour sauver deux lignes.
# Une note pour indiquer que les valeurs à remplacer pourrait
# être fait en une seule ligne de syntaxe en bénéficiant du
# recyclage vectoriel de R, mais la solution n'est ni simple,
# ni élégante.
remplacer = cbind(c(rep(i, i-1), 1:(i-1)), c(1:(i-1), rep(i, i-1)))
S[remplacer]Trêve de digression, une fois la matrice de covariance S calculée, la fonction MASS::mvrnorm() peut être utilisée pour créer des données. Les résultats sont presque identiques pour les régressions.
# La même que l'exemple précédent
set.seed(1448)
# Création de données
X <- MASS::mvrnorm(n = n, mu = c(0, 0, 0), Sigma = S)
# Configurer en tableau de données (data.frame)
X <- as.data.frame(X)
colnames(X) = c("x1","x2","x3")
# Retrouver beta21
lm(x2 ~ x1, data = X)
>
> Call:
> lm(formula = x2 ~ x1, data = X)
>
> Coefficients:
> (Intercept) x1
> -0.00219 0.20191
# Retrouver beta31 et beta32
lm(x3 ~ x1 + x2, data = X)
>
> Call:
> lm(formula = x3 ~ x1 + x2, data = X)
>
> Coefficients:
> (Intercept) x1 x2
> -0.00579 0.40295 -0.49899Comme la formule est générale et implique plusieurs itérations, il est envisageable de programmer ces calculs avec une boucle dans une fonction maison. La fonction maison beta2cov() permet, à partir d’une matrice de coefficient de régression et d’un vecteur de variance, d’obtenir la matrice de covariance.
# De Beta vers covariance (beta 2 covariance)
beta2cov <- function(B, V = NULL){
p <- dim(B)[1] # Nombre de variables
if(is.null(V)){ # Si V est nulle, alors V est une
S <- diag(p) # matrice diagonale d'identité,
}else{ # autrement il s'agit d'une matrice
S <- diag(V) # avec les variances en diagonale
}
# Boucle de calcul pour la covariance
# de la variable i (i = 2:p)
for(i in 2:p){
COV <- B[(i), (1:(i-1))] %*% S[1:(i-1), 1:(i-1)]
S[i, 1:(i-1)] <- COV
S[1:(i-1), i] <- COV
}
return(S)
}Évidemment, comme il est possible de passer d’une matrice de coefficient de régression à une matrice de covariance, l’inverse est envisageable. Lorsque l’équation (15.24) est réarrangée pour isoler \(\mathbf{B}\), l’équation (15.25) est obtenue.
\[\begin{equation} \mathbf{B}_{i+1, 1:i} = \mathbf{\Sigma}^{-1}_{1:i,1:i}\mathbf{\Sigma}_{1+i,1:i} \tag{15.25} \end{equation}\]
L’équation (15.25) se transforme (relativement) aisément en fonction maison. Par rapport à beta2cov(), la boucle n’inclut pas la \(p\)e variable, mais bien la première.
# De la covariance à Beta (cov2beta)
cov2beta <- function(S){
p <- ncol(S) # Nombre de variable
BETA <- matrix(0, p, p) # Matrice vide
# Boucle de calcul pour la covariance
# de la variable i (i = 1:(p-1))
for(i in 1:(p-1)){
BETA[i+1, 1:i] <- solve(S[1:i, 1:i], S[1+i, 1:i])
}
return(BETA)
}La fonction maison cov2beta() est maintenant testée sur S pour évaluer si elle retourne bien la matrice B originale.
Ce qui est le cas.
Une seule contrainte s’impose lors de la du calcul de la covariance à partir des coefficients de régression. Il s’agit de s’assurer que la matrice de covariance demeure positive semi-définie à chaque étape. Cela se manifeste notamment lorsque les coefficients de régression pour une variable dépendante sont si élevés que le coefficient de détermination surpasse la variance de la variable en question. Autrement dit, la variance de la variable n’est pas assez élevée pour le potentiel explicatif. Mathématiquement, le problème revient à \(1-R^2_X < 0\) ou plus généralement à \(\sigma^2_y-\mathbf{B^\prime\Sigma B}<0\). Dans un tel cas, la variance résiduelle est négative, ce qui est impossible. Cette situation correspond à une variance expliquée de plus de 100%, Autrement dit, la somme des parts d’informations (variables prédictrices plus les résidus) est plus grande que l’information totale. Les corrections possibles sont de réduire les coefficients de régression \(\mathbf{B}\) ou bien d’augmenter la variance de \(\sigma^2_y\) de sorte que \(\sigma^2_y-\mathbf{B^\prime\Sigma B}>=0\) soit toujours vraie à chaque étape.
Dernièrement, comme ces équations et syntaxes procèdent de \(i=2,...,p\), l’ordre des variables est primordiale. En altérer leur ordre amène des conséquences substantielles sur les résultats. Lorsque la matrice \(\mathbf{B}\) est créée, il faut être certain de l’ordre déterministe des variables, c’est-à-dire, quelle variable cause quelles autres variables. Changer ou retirer ne serait-ce qu’une variable altère les coefficients de régression. Les analyses de régression ne correspondront plus à celles attendues. Il ne faut pas se surprendre si les résultats changent dans une telle situation. Nonobstant, changer ou retirer une variable peut être pertinent dans certains contextes, surtout dans le contexte de l’étude de la méspécification (misspecification en anglais) des modèles, c’est-à-dire lorsqu’un modèle erroné est utilisé plutôt que le vrai modèle, ce qui entraîne notamment des biais. Les études à ce sujet empruntent une méthode statistique similaire à celle décrite dans ce chapitre.