22 Classer
En plus d’essayer de regrouper des variables ensemble, il est aussi possible d’essayer de regrouper les participants en groupes. Il s’agit de l’analyse de classes latentes (LCA) et de l’analyse de profils latents (LPA). La LCA et la LPA se distinguent par le type de variables qu’elles considèrent, soit les variables continues (LPA) ou catégorielles (LCA). Ces techniques sont utiles lorsque l’expérimentateur souhaite réduire l’échantillon en sous-groupes afin de mieux comprendre les participants. Elles peuvent notamment permettre de décrire les profils de compétences et de difficultés parmi les enfants d’âge préscolaire, en identifiant ceux qui peuvent avoir besoin d’interventions éducatives spécifiques ou encore de décrire des groupes de résilience à la violence conjugale et de mieux orienter les interventions auprès des personnes ayant été victimes d’agressions sexuelles.
Ces analyses issues des modèles de mixture (mixture modelling) sont similaires aux techniques de regroupement (clustering), mais s’en distinguent car elles reposent sur un modèle explicite et prennent en compte le fait que les groupes identifiés sont incertains. Le modèle sous-jacent est présenté à la Figure 22.1.
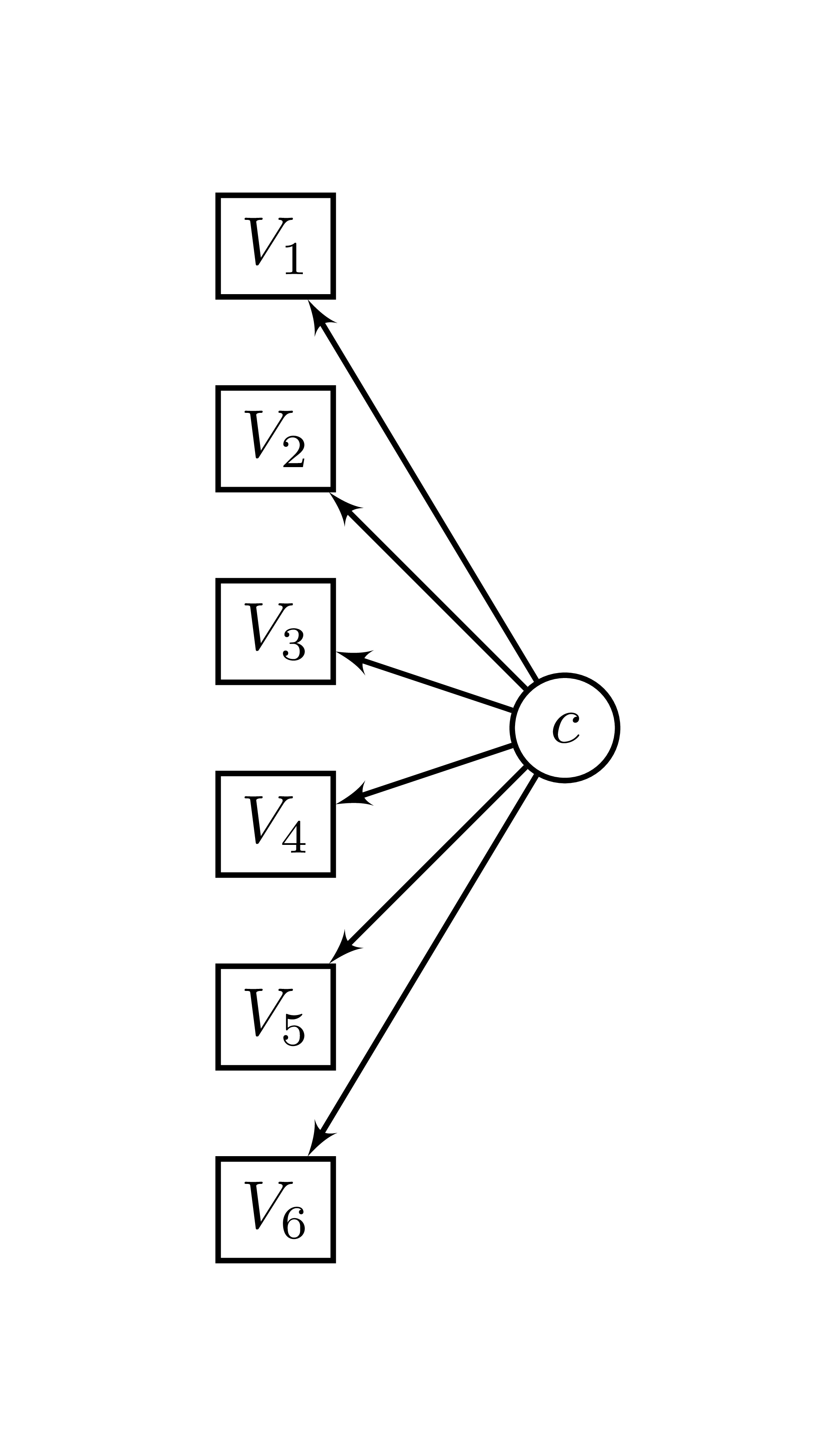
Figure 22.1: Modèle de classes latentes.
La LCA et la LPA sont considérées comme plus robustes que les autres techniques, comme le k-mean, par exemple, parce qu’elle repose sur un modèles théorique. Cela revient au détriment d’être plus intensif computationnellement, ce qui pourra soulever des problèmes à l’ocassion, surtout pour la LCA. Néanmoins, il demeure que les techniques de regroupement sont en quelque sorte un bricolage. Au final, c’est la solution qui fera le plus de sens sur le plan théorique qui sera retenue. Même si les statistiques suggéreront un certain nombre de classes, elles ne seront pas toujours en harmonie entre elles. C’est la simplicité et le pouvoir explicatif qui devra être l’ultime décideur.
22.1 Classes latentes
L’analyse de classes latentes (LCA) permet de partager et de distinguer des sous-groupes non observables (latents) d’individus sur la base de leurs réponses à un ensemble d’indicateurs observables (manifestes) ordinaux. Elle fait ainsi partie de la famille des finite mixture modelling. Il s’agit d’une analyse exploratoire de la même façon que les analyses factorielles exploratoires. Elle se distingue des analyses factorielles qui tentent plutôt de regrouper les indicateurs en facteurs (ou groupes), alors que la LCA tente plutôt de regrouper les participants en groupes.
22.1.1 Installations
Il existe un package permettant de réaliser la LCA avec R, soit poLCA. Ce package bien qu’excellent pour réaliser la LCA demeure relativement incomplet et mérite quelques améliorations. C’est pourquoi le package poLCAExtra est recommandé. Installer poLCAExtra installera du même coup le package poLCA.
# Version en développement sur GitHub
remotes::install_github(repo = "quantmeth/poLCAExtra")Une fois téléchargé, comme toujours, il faut appeler le package.
library(poLCAExtra)22.1.2 Déterminer le nombre de classes
La première étape est de déterminer le nombre de classes. Pour ce faire, on importe le jeu de données, ici ex1.poLCA, un jeu de données de poLCAEXtra. On spécifie ensuite le modèle dans une formule.
jd <- ex1.poLCA
f1 <- cbind(V1, V2, V3, V4, V5, V6) ~ 1Comme la Figure 22.1 montre, les items sont les variables dépendantes et comme la MANOVA, il faut indiquer ces variables à gauche de la formule en les liant avec cbind(), comme cbind(V1, V2, V3, V4, V5, V6). Le ~ délimite les variables dépendantes (gauche) et indépendantes (droite). L’utilisation de 1 indique la seule présence d’une constante, soit que le classement se fasse directement sur les variables. Il est possible d’ajouter des covariables pour contrôler des effets dans les variables dépendantes si l’utilisateur le juge nécessaire de la même qu’un [modèle linéaire][L’analyse de régression avec R].
Ensuite, il faut rouler différentes valeurs de nombre de classes en incrément de 1.
LCA1 <- poLCA(f1, data = jd, nclass = 1, verbose = FALSE)
LCA2 <- poLCA(f1, data = jd, nclass = 2, verbose = FALSE)
LCA3 <- poLCA(f1, data = jd, nclass = 3, verbose = FALSE)
LCA4 <- poLCA(f1, data = jd, nclass = 4,
maxiter = 500, nrep = 4, verbose = FALSE)La fonction poLCA() prend en argument le jeu de données et la formule et le nombre de classes à rechercher. L’argument verbose = FALSE évite de polluer la console avec toutes les sorties de la fonction. Autrement, la fonction produit automatiquement la sortie même s’il y a assignation. Plus il y a de classes, plus le modèle est difficile à évaluer, c’est pourquoi à nclass = 4, les options maxiter et nrep sont ajoutées. Ces arguments augmenteront le nombre maximal d’itérations et le nombre de répétions de départ, ce qui permettra d’assurer une meilleur estimation du modèle et aussi une meilleure stabilité. Bien que cela dépend de plusieurs facteurs, ces options deviennent obligatoires vers quatre classes. Et plus le modèle devient compliqué, plus ces valeurs devront augmenter. Il n’y a pas de critères définitifs pour ces valeurs, outre que plus, c’est mieux, mais plus long à calculer.
Pour les comparer, le package poLCAExtra permet la comparaison automatique des modèles avec la fonction anova().
anova(LCA1, LCA2, LCA3, LCA4)
> nclass df llike AIC BIC Rel.Entropy LMR p
> 1 57 -2688 5388 5416
> 2 50 -2365 4757 4817 0.803 614.576 < .001
> 3 43 -2196 4432 4525 0.840 322.830 < .001
> 4 36 -2190 4435 4561 0.871 10.574 0.158
> Classes.size
> 800
> 373|427
> 101|345|354
> 49|73|324|354Plus simplement, à l’aide de poLCAExtra, ces deux derniers chunks pourraient être remplacés par celui-ci qui teste toutes les classes de 1:4.
LCAE <- poLCA(f1, data = jd, nclass = 1:4,
maxiter = 500, nrep = 4)Dans cette sortie, plusieurs éléments pourront guider la décision sur le nombre de classes. Généralement, on recourt au AIC, au BIC et à l’entropie relative. Idéalement, il faut que le AIC et le BIC soient le plus faible possible avec des bonds importants entre chaque nombre de classes. Dans ce cas-ci ces deux indices commencent à augmenter à nclass = 4, ce qui laisse suggérer que trois classes est une bonne solution. Une autre recommandation est une entropie relative supérieure à .80. Il s’agit d’un indice allant de 0 à 1, le plus élevé étant meilleur. Ici aussi, le modèle à quatre classes n’est pas soutenu, puisque la valeur est inférieure à la recommandation.
Il faudra jeter un regard à la taille des classes afin d’éviter des classes trop petites ou disproportionnées. Ces tailles varieront inévitablement d’une question de recherche à l’autre, mais il faut y porter attention. Ici, elles semblent toutes adéquates sauf l’option à deux classes. Un dernier test souvent utilisé est le test de vraisemblance de Lo-Mendell-Rubin (LMR) qui fournit une valeur-p. Ce test suggère un nombre de classes jusqu’au premier modèle non-significatif (exclusivement). Ici, le LMR suggère trois classes, car la quatrième classe est non-significative au seuil de 5%. Ce test a tendance a être très libéral, il faut y recourir avec discernement.
22.1.3 Inspections
Une des hypothèses de la LCA est l’indépendance locale, soit qu’une fois les classes retirées, les variables observées sont indépendantes les unes des autres. Cela se traduit par l’absence de patterns entre les items non qui ne sont pas tenus en compte par les classes. Pour vérifier cela, poLCAExtra ajoute la fonction poLCA.tech10() pour vérifier les patterns.
poLCA.tech10(LCA3)
> The 20 most frequent patterns
>
> pattern observed expected z chi llik.contribution
> 111111 200 201.26 -0.09 0.01 -2.50
> 122121 166 165.34 0.05 0.00 1.32
> 112121 48 47.67 0.05 0.00 0.66
> 121121 42 46.13 -0.61 0.37 -7.88
> 122111 39 37.76 0.20 0.04 2.52
> 111121 38 32.91 0.89 0.79 10.93
> 111211 32 30.69 0.24 0.06 2.67
> 222222 29 28.14 0.16 0.03 1.75
> 111112 25 27.20 -0.42 0.18 -4.22
> 112111 23 28.33 -1.00 1.00 -9.58
> 121111 22 18.61 0.79 0.62 7.37
> 122222 11 12.68 -0.47 0.22 -3.13
> 122122 10 10.90 -0.27 0.07 -1.72
> 211111 10 7.97 0.72 0.51 4.53
> 222122 9 8.92 0.03 0.00 0.16
> 122221 8 5.43 1.10 1.22 6.20
> 112112 7 2.99 2.32 5.38 11.91
> 221222 7 6.79 0.08 0.01 0.43
> 111212 6 4.25 0.85 0.72 4.14
> 112222 6 2.55 2.16 4.65 10.25
> p check
> 0.46
> 0.48
> 0.48
> 0.27
> 0.42
> 0.19
> 0.41
> 0.44
> 0.34
> 0.16
> 0.22
> 0.32
> 0.39
> 0.24
> 0.49
> 0.13
> 0.01 *
> 0.47
> 0.20
> 0.02 *
>
> Number of observed patterns: 50
> Number of empty cells: 14
> Total number of possible patterns: 64Un certain nombre de patterns statistiquement significatifs est à prévoir. Les plus problématiques sont ceux ayant des fréquences observées fréquentes (les premières listées). Il est vraisemblable que les plus petites fréquences engendrent des contributions plus importantes. Une règle est de vérifier si le nombre de checks est inférieur à 5% du nombre de patterns. Ici, il y 50 patterns, ce qui donne \(.05*50=2.5\) patterns et comme il n’y a que deux patterns statistiquement significatifs, \(2.5 > 2\), ces patterns peuvent être ignorés. Cependant, s’il y a avait plus de checks touchant des patterns plus fréquent, il faudrait remédier à la situation, soit en retirant ou en ajoutant des items ou, plus simplement, en augmentant le nombre de classes.
En effet, en plus de vérifier l’indépendance locale, l’inspection des patterns permet de vérifier l’adéquation du nombre de classes, car s’il y a trop peu de classes, il y aura beaucoup de patterns statistiquement significatifs.
22.1.4 Représentations graphiques
La représentation graphique des classes peut se faire facilement avec la fonction plot() en y mettant la sortie de poLCA().
plot(LCA3)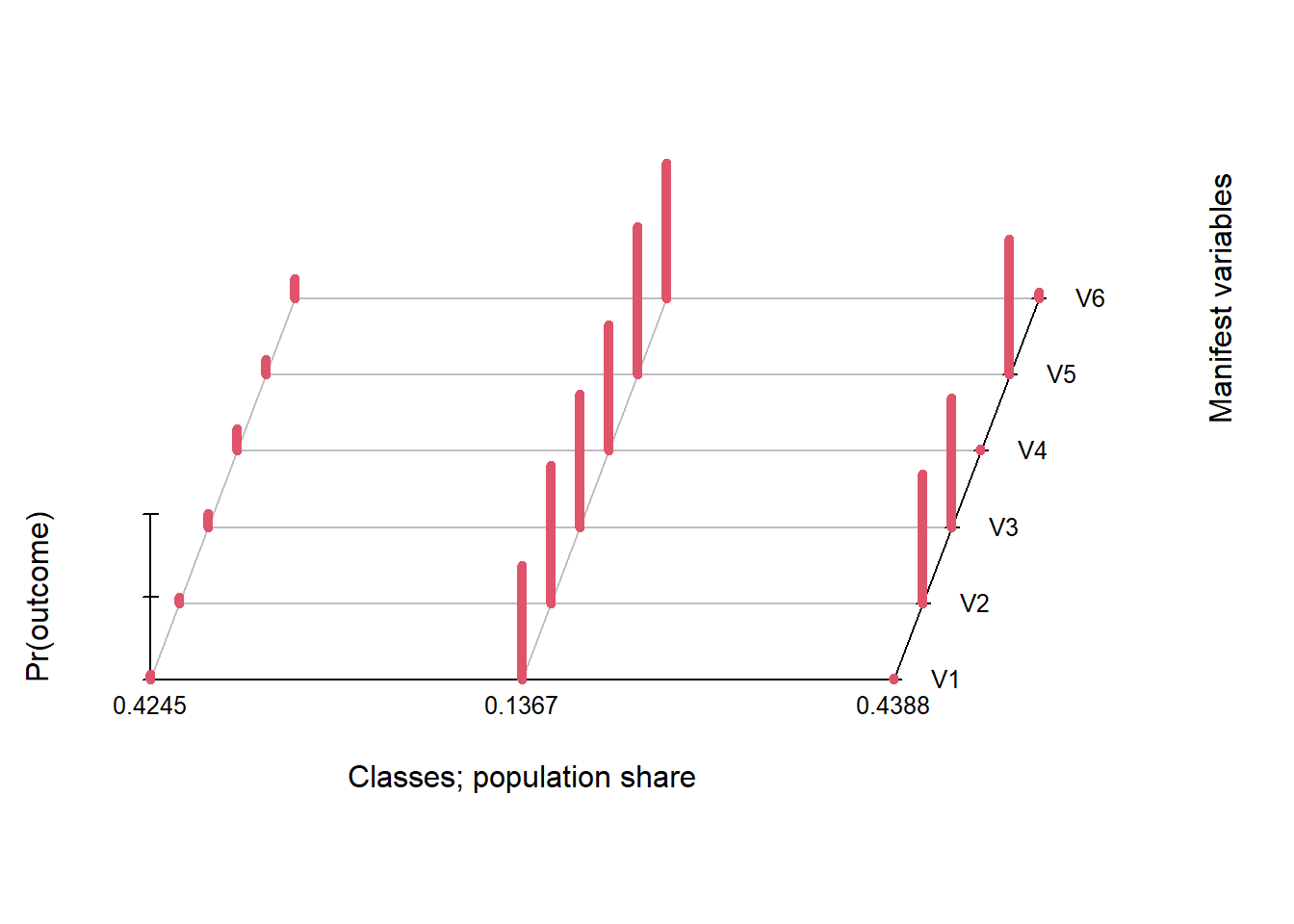
Figure 22.2: Analyse visuelle des classes.
La Figure 22.2 montre sur l’axe des \(x\) (largeur), les classes avec les proportions, sur l’axe des \(z\) (profondeur), il s’agit des différents items utilisés pour la classification et sur l’axe des \(y\), la probabilité qu’une personne de la classe \(x\) ait choisi une certaine réponse à l’item \(z\). Si les items permettaient plus de choix de réponses (une échelle a plus de deux options), la figure s’ajusterait en conséquence.
Une autre façon de présenter les données avec ggplot2 est cette figure.
poLCA.plot(LCA3)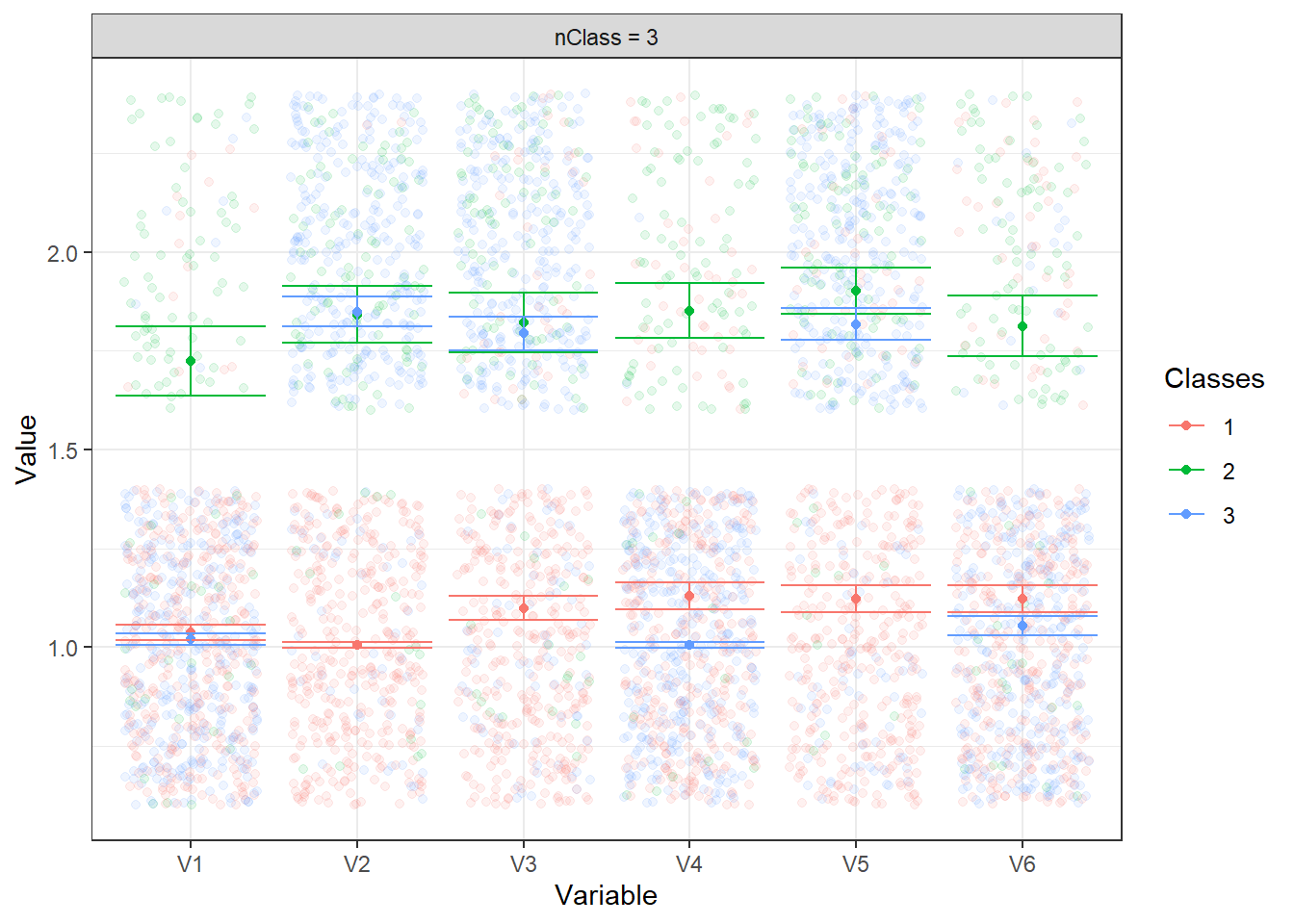
Figure 22.3: Analyse visuelle supplémentaire des classes.
Cette méthode sera plus similaire à l’analyse de profils latents.
22.1.5 Analyses supplémentaires
L’expérimentateur souhaite parfois tester si les classes se comparent sur d’autres variables. Dans ces cas, il faut tenir compte de la probabilité d’appartenir à l’une des classes et non pas utiliser uniquement la classe prédite (la plus probable). Cela entraînerait des biais statistiques. Par exemple, un participant ayant 33 %, 33 % et 34 %, se verrait attribuer à la troisième classe, même si, au fond, il pourrait bien appartenir à l’une des deux autres. Les analyses three-step (ou 3step) sont développées justement pour tenir compte de ces probabilités. Il y a deux fonctions principales r3step() pour les variables continues et d3step() pour les variables nominales et catégorielles.
Pour une variable à échelle continue, r3step() fonctionne avec la sortie correspondant au nombre approprié de classes et avec le nom de la variable dépendante ou une formule comme continue ~ 1.
res.r3 <- r3step("continuous", LCA3)Il est possible d’obtenir une représentation graphique ainsi.
plot(res.r3)
> Warning in fortify(data, ...): Arguments in `...` must be used.
> ✖ Problematic argument:
> • size = 5
> ℹ Did you misspell an argument name?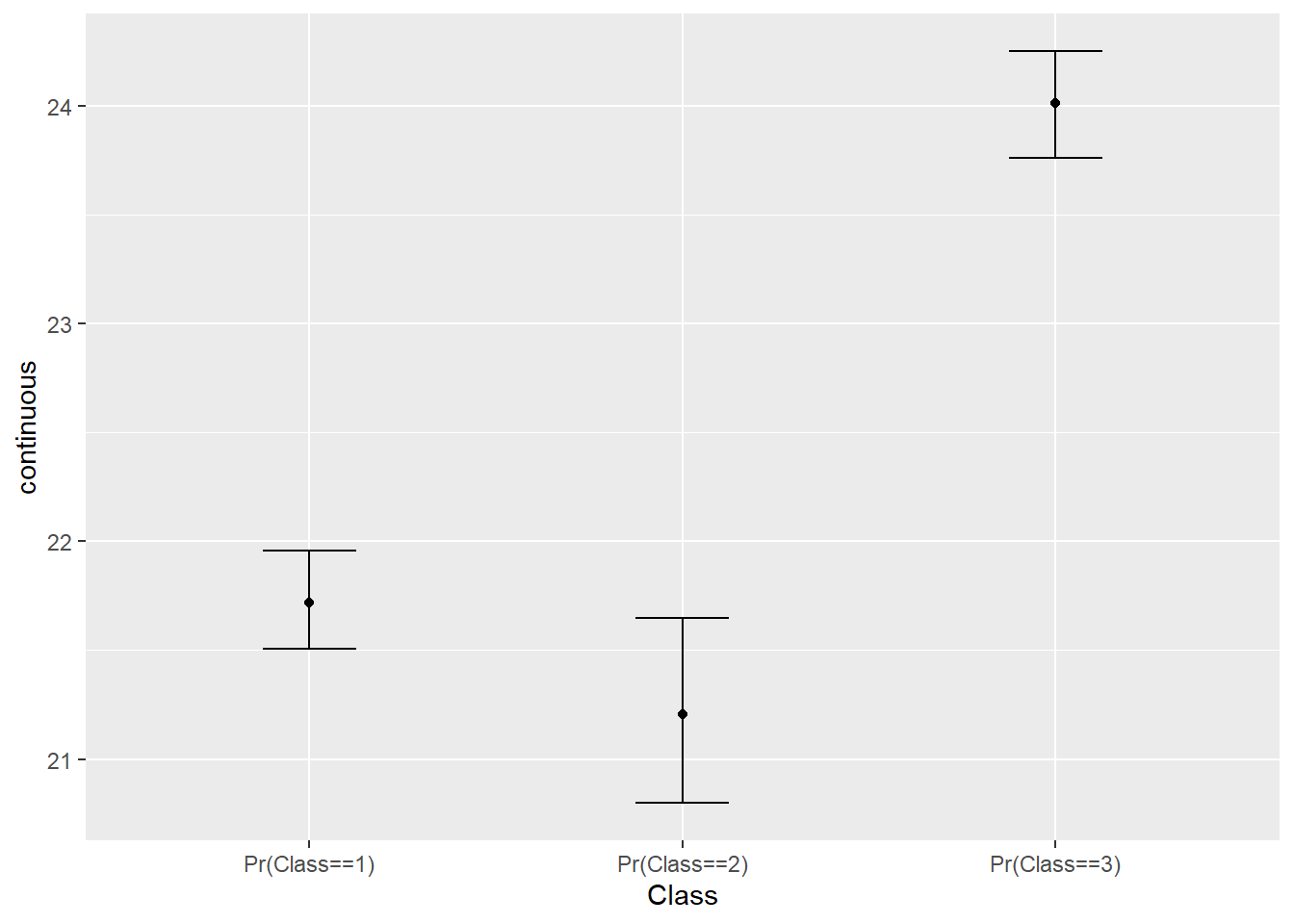
Figure 22.4: r3step des classes.
Pour une variable à échelle nominale, d3step() fonctionne avec la sortie avec le nombre approprié de classes ainsi que le nom de la variable dépendante ou une formule comme categorical ~ 1.
res.d3 <- d3step("categorical", LCA3)Cette fonction possède aussi une représentation graphique.
plot(res.d3)
> Warning in fortify(data, ...): Arguments in `...` must be used.
> ✖ Problematic argument:
> • size = 5
> ℹ Did you misspell an argument name?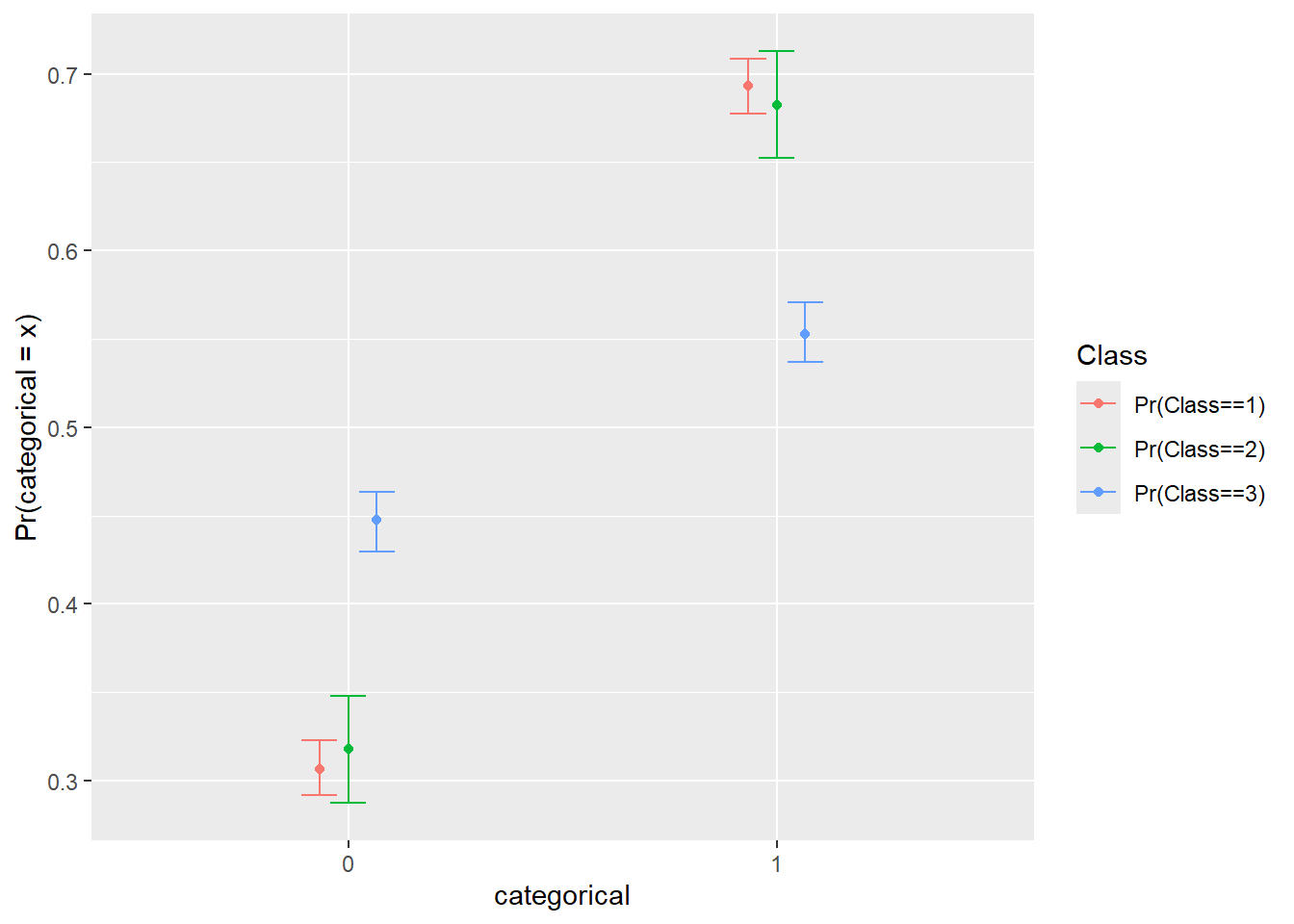
Figure 22.5: r3step des classes.
22.1.6 Quelques conseils utiles
Une fois l’analyse terminée, il est recommandé de rouler une dernière fois l’analyse avec une graine et les arguments nrep et maxiter pour s’assurer de la stabilité et de la répétabilité des résultats.
22.2 Profils latents
Pour les profils latents, le package suivant est nécessaire. Il faut d’abord l’installer, puis l’appeler.
Le package tidyLPA est compatible avec l’environnement du tidyverse.
Pour effectuer l’analyse de profils latents, il faut sélectionner les variables pour l’analyse avec la fonction select. Dans la fonction estimate_profiles, il faut spécifier le nombre de profils à investiguer. Ici, le jeu de données ex3.tidyLPA de poLCAExtra est utilisé.
jd <- ex3.tidyLPA
LPA1_5 <- jd %>%
select(V1, V2, V3, V4, V5) %>%
estimate_profiles(1:5)
LPA1_5
> tidyLPA analysis using mclust:
>
> Model Classes AIC BIC Entropy prob_min prob_max
> 1 1 1 7170.48 7207.52 1.00 1.00 1.00
> 2 1 2 5949.93 6009.19 0.96 0.98 0.99
> 3 1 3 4934.20 5015.68 1.00 1.00 1.00
> 4 1 4 4936.30 5040.00 0.91 0.62 1.00
> 5 1 5 4947.38 5073.31 0.82 0.39 1.00
> n_min n_max BLRT_p
> 1 1.00 1.00
> 2 0.35 0.65 0.01
> 3 0.33 0.33 0.01
> 4 0.08 0.33 0.20
> 5 0.06 0.33 0.99Comme les analyses de classes latentes, il faut procéder étape par étape pour déterminer le nombre de classes. Dans estimate_profiles(), on peut directement inscrire toutes les classes à investiguer. Le meilleur nombre de classes se base sur des AIC et BIC les plus bas possibles et une entropie relative42 de plus de .80. Il est aussi possible de se baser sur le BLRT_p, soit la valeur-\(p\) d’un test de ratio de vraisemblance bootstrapé (similaire au Lo-Mendell-Rubin présenté dans les classes latentes).
Dans cet exemple, il est possible de générer des graphiques pour comparer certains indices d’ajustement, notamment l’AIC, le BIC et l’entropie à l’aide de la fonction plot.
plot(LPA1_5, statistics = 'AIC')
plot(LPA1_5, statistics = 'BIC')
plot(LPA1_5, statistics = 'Entropy')Une fois le nombre de classes décidé, il faut rouler à nouveau l’analyse avec le nombre désiré.
LPA3 <- jd %>%
select(V1, V2, V3, V4, V5) %>%
estimate_profiles(3)Pour connaître le nombre de participants (n) dans chaque profil, il faut procéder ainsi.
get_data(LPA3) %>%
group_by(Class) %>%
count()
> # A tibble: 3 × 2
> # Groups: Class [3]
> Class n
> <dbl> <int>
> 1 1 100
> 2 2 100
> 3 3 100Finalement, il est possible générer la représentation graphique du modèle choisi (et des autres modèles si besoin) à l’aide de la fonction plot_profiles.
LPA3 %>%
plot_profiles()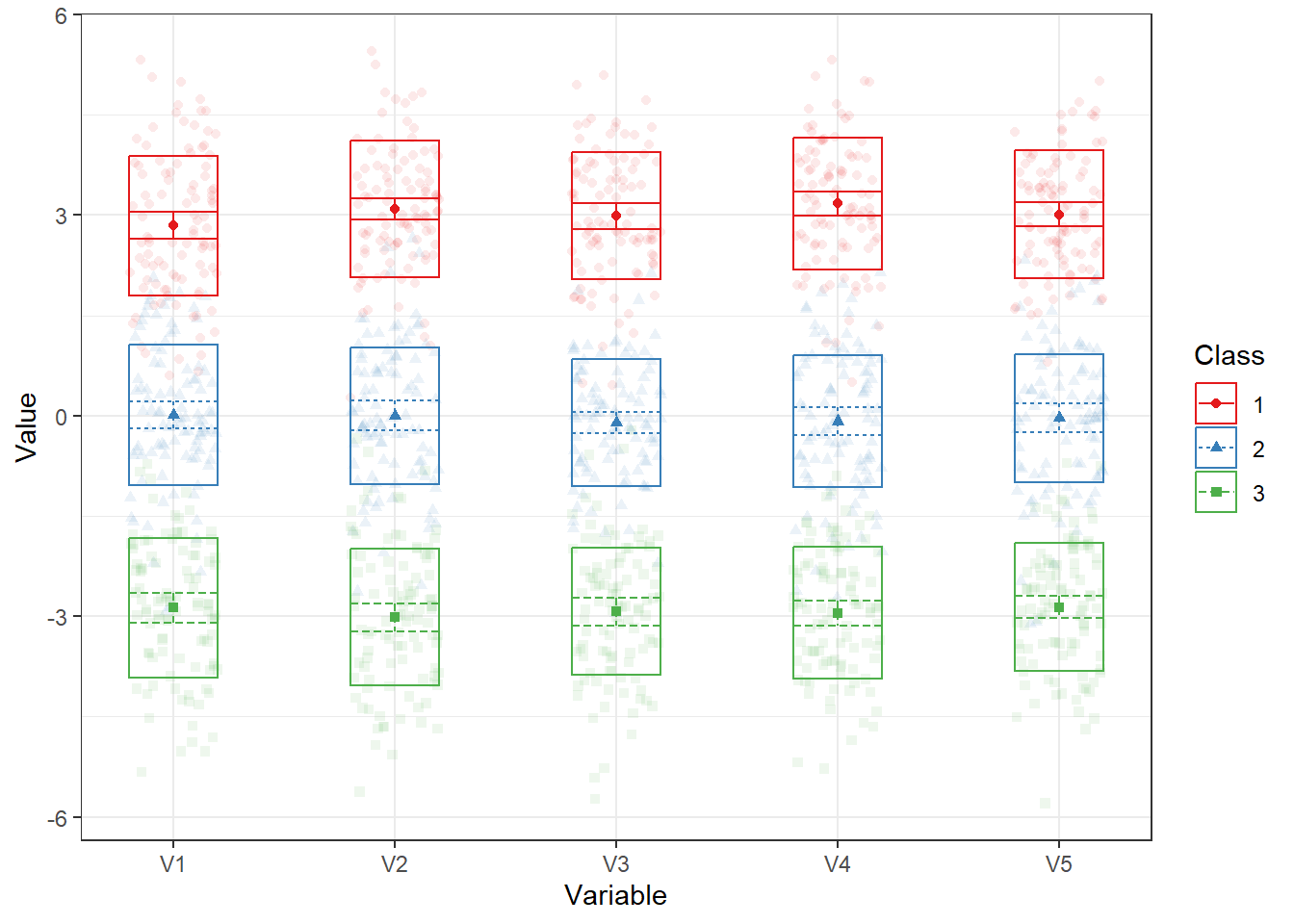
Figure 22.6: Analyse visuelle des profils.
La Figure 22.6 permet de visusalier le profil des réponses des participants selon les items.
Enfin, différents types de modèles sont possibles. Le Tableau 22.1 en dénombre six disponibles dans le package tidyLPA et présente leurs caractéristiques.
| Model | Variance | Covariance |
|---|---|---|
| 1 | equal | zero |
| 2 | varying | zero |
| 3 | equal | equal |
| 4 | varying | equal |
| 5 | equal | varying |
| 6 | varying | varying |